一、DFS和BFS
| 数据结构 | 空间 | 备注 | |
|---|---|---|---|
| DFS | stack | $O(h)$(树的高度相关,记录路径) | 算法思路奇怪或对空间要求较高 |
| BFS | queue | $O(2^h)$(树的层相关,记录一层) | 具有最短路径的性质,用于最小步数、最少操作几次等问题 |
1.1 DFS
回溯/剪枝、恢复现场
#include<iostream>
using namespace std;
const int N = 10;
int n;
int path[N]; // 路径保存(存储方案)
bool st[N]; // 检验这个点是否被用过
void dfs(int u)
{
if (u == n) // 递归到最后一层
{
for (int i = 0; i < n; i++)
printf("%d ", path[i]);
puts("");
return;
}
for (int i = 1; i <= n; i++) // 未递归到最后一层
{
if (!st[i]) // 如果该点未被使用过
{
path[u] = i; // 将该点记录
st[i] = true;
dfs(u + 1);
st[i] = false; // 恢复现场
}
}
}
int main()
{
cin >> n;
dfs(0);
return 0;
}- 第一种搜索顺序:按行枚举
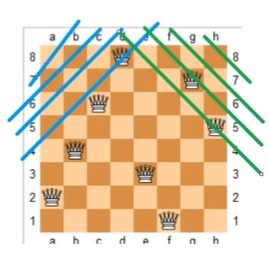
注:
y - x可能是负数,所以后面的算法中添加了偏移量n,使其一直为正数。
#include<iostream>
using namespace std;
const int N = 20; // 对角线需要两倍的n
int n;
char g[N][N]; // 存储棋子情况
bool col[N], dg[N], udg[N]; // 列、对角线、反对角线情况
void dfs(int u)
{
if (u == n)
{
for (int i = 0; i < n; i++)
puts(g[i]); // 输出每行的棋子情况
puts("");
return;
}
for (int i = 0; i < n; i++)
{
if (!col[i] && !dg[u + i] && !udg[n - u + i]) // 枚举各列
{
g[u][i] = 'Q';
col[i] = dg[u + i] = udg[n - u + i] = true; // 记录为true
dfs(u + 1);
col[i] = dg[u + i] = udg[n - u + i] = false; // 恢复现场
g[u][i] = '.';
}
}
}
int main()
{
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
g[i][j] = '.';
dfs(0);
return 0;
}- 第二种搜索顺序:一个一个格子进行搜索
#include<iostream>
using namespace std;
const int N = 20; // 对角线需要两倍的n
int n;
char g[N][N]; // 存储棋子情况
bool row[N],col[N], dg[N], udg[N]; // 行、列、对角线、反对角线情况
void dfs(int x,int y,int s) // 行列坐标及当前皇后的数量
{
if (y == n)
y = 0, x++;
if (x == n)
{
if (s == n) // 找到了一种成功的方案
{
for (int i = 0; i < n; i++) puts(g[i]);
puts("");
}
return;
}
// 枚举两种情况:不放皇后
dfs(x, y + 1, s);
// 放皇后
if (!row[x] && !col[y] && !dg[x + y] && !udg[x - y + n])
{
g[x][y] = 'Q';
row[x] = col[y] = dg[x + y] = udg[x - y + n] = true;
dfs(x, y + 1, s + 1);
row[x] = col[y] = dg[x + y] = udg[x - y + n] = false;
g[x][y] = '.'; //恢复现场
}
}
int main()
{
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
g[i][j] = '.';
dfs(0, 0, 0);
return 0;
}翰翰和达达饲养了 $N$ 只小猫,这天,小猫们要去爬山。经历了千辛万苦,小猫们终于爬上了山顶,但是疲倦的它们再也不想徒步走下山了。翰翰和达达只好花钱让它们坐索道下山。
索道上的缆车最大承重量为 $W$,而 $N$ 只小猫的重量分别是 $C_1,C_2,C_N$。
当然,每辆缆车上的小猫的重量之和不能超过 $W$。
每租用一辆缆车,翰翰和达达就要付 11 美元,所以他们想知道,最少需要付多少美元才能把这 $N$ 只小猫都运送下山?
剪枝原则:
- 优化搜索顺序:大部分情况下,我们应该优先搜索分支较少的节点
- 排除等效冗余
- 可行性剪枝
- 最优性剪枝
- 记忆化搜索(DP)
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 20;
int n, m;
int w[N];
int sum[N];
int ans = N;
void dfs(int u, int k)
{
// 最优性剪枝
if (k >= ans) return;
if (u == n)
{
ans = k; // k一定小于ans
return;
}
for (int i = 0; i < k; i ++ )
if (sum[i] + w[u] <= m) // 可行性剪枝
{
sum[i] += w[u];
dfs(u + 1, k);
sum[i] -= w[u]; // 恢复现场
}
// 新开一辆车
sum[k] = w[u];
dfs(u + 1, k + 1);
sum[k] = 0; // 恢复现场
}
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i ++ ) cin >> w[i];
// 优化搜索顺序, w从大到小排序
sort(w, w + n);
reverse(w, w + n);
dfs(0, 0);
cout << ans << endl;
return 0;
}$100$ 可以表示为带分数的形式:$100=3+\frac{69258}{714}$,还可以表示为:$100=82+\frac{3546}{197}$
注意特征:带分数中,数字 $1∼9$ 分别出现且只出现一次(不包含 $0$)。
类似这样的带分数,$100$ 有 $11$ 种表示法。
请输出输入数字用数码 $1∼9$ 不重复不遗漏地组成带分数表示的全部种数。
枚举:由 $n = a + \frac{b}{c}$,得 $cn=ca+b$,只需枚举 $a,c$,判断 $b$ 是否成立即可。
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10;
int n;
bool st[N], backup[N];
int ans;
bool check(int a, int c)
{
long long b = n * (long long)c - a * c;
if (!a || !b || !c) return false;
memcpy(backup, st, sizeof st);
while (b)
{
int x = b % 10; // 取个位
b /= 10; // 个位删掉
if (!x || backup[x]) return false;
backup[x] = true;
}
for (int i = 1; i <= 9; i ++ )
if (!backup[i])
return false;
return true;
}
void dfs_c(int u, int a, int c)
{
if (u > 9) return;
if (check(a, c)) ans ++ ;
for (int i = 1; i <= 9; i ++ )
if (!st[i])
{
st[i] = true;
dfs_c(u + 1, a, c * 10 + i);
st[i] = false;
}
}
void dfs_a(int u, int a)
{
if (a >= n) return;
if (a) dfs_c(u, a, 0); // 嵌套 DFS
for (int i = 1; i <= 9; i ++ )
if (!st[i])
{
st[i] = true;
dfs_a(u + 1, a * 10 + i); // 在数后加上一位 i, 递归下一层
st[i] = false;
}
}
int main()
{
cin >> n;
dfs_a(0, 0);
cout << ans << endl;
return 0;
}1.2 BFS
当所有边的权重都为1时,才可以使用 BFS 求解最短路径问题。
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 110;
int n, m;
int g[N][N]; // 存储地图
int d[N][N]; // 存储最短路径
PII q[N * N];
int bfs()
{
int hh = 0, tt = 0; // 定义空队列
q[0] = { 0,0 }; // 记录开始点坐标
memset(d, -1, sizeof d); // 初始化最短距离为-1
d[0][0] = 0;
// 向量表示(-1,0),(0,1),(1,0),(0,-1)
int dx[4] = { -1,0,1,0 }, dy[4] = { 0,1,0,-1 };
while (hh <= tt)
{
auto t = q[hh++]; // 将队首元素出队
for (int i = 0; i < 4; i++)
{
int x = t.first + dx[i], y = t.second + dy[i];
if (x >= 0 && x < n && y >= 0 && y < m && g[x][y] == 0 && d[x][y] == -1)
{
// g数组等于0表示该点是路径上的点,d数组为-1表示未被选过
d[x][y] = d[t.first][t.second] + 1;
q[++tt] = { x,y }; // 将该点记录
}
}
}
return d[n - 1][m - 1];
}
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
cin >> g[i][j];
cout << bfs() << endl;
return 0;
}若需要输出路径,则可以在 d[x][y] = d[t.first][t.second] + 1; 后添加一句代码用于存储当前元素的前一个元素 Prev[x][y] = t;【记录路径】,然后在函数返回前输出路径:
int x = n - 1, y = m - 1;
while(x || y)
{
cout << x << ' ' << y << endl;
auto t = Prev[x][y];
x = t.first, y = t.second;
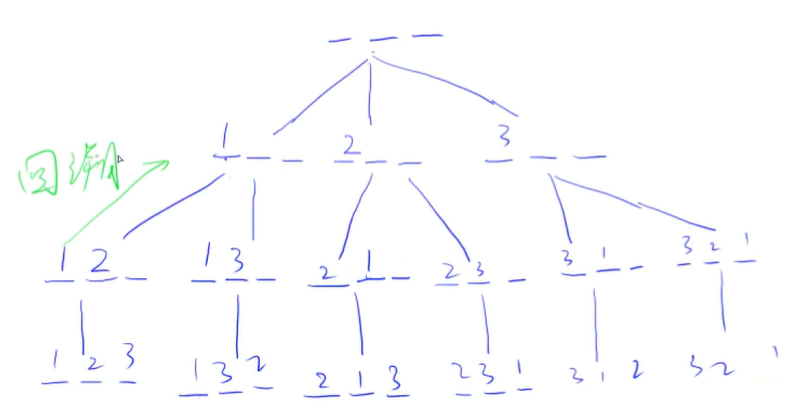
}在一个 $3×3$ 的网格中,$1∼8$ 这 $8$ 个数字和一个 x 恰好不重不漏地分布在这 $3×3$ 的网格中。
例如:
1 2 3
x 4 6
7 5 8在游戏过程中,可以把 x 与其上、下、左、右四个方向之一的数字交换(如果存在)。
我们的目的是通过交换,使得网格变为如下排列(称为正确排列):
1 2 3
4 5 6
7 8 x例如,示例中图形就可以通过让 x 先后与右、下、右三个方向的数字交换成功得到正确排列。
交换过程如下:
1 2 3 1 2 3 1 2 3 1 2 3
x 4 6 4 x 6 4 5 6 4 5 6
7 5 8 7 5 8 7 x 8 7 8 x给定一个初始网格,求出得到正确排列至少需要进行多少次交换。
思路:将每个状态看成图中的一个结点,用字符串保存状态
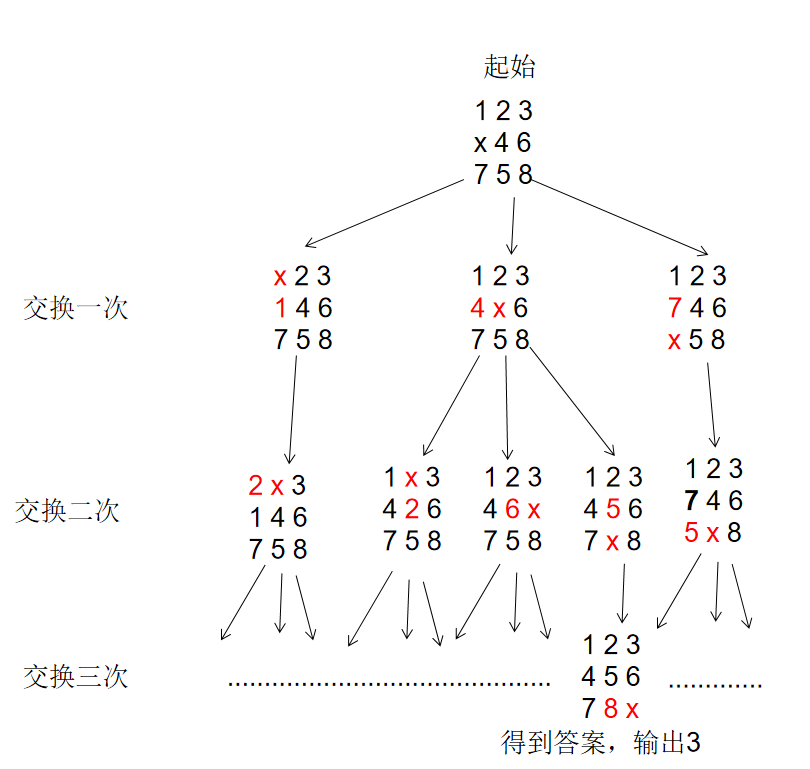
#include <iostream>
#include <algorithm>
#include <unordered_map>
#include <queue>
using namespace std;
int bfs(string state)
{
queue<string> q;
unordered_map<string, int> d;
q.push(state);
d[state] = 0;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
string end = "12345678x";
while (q.size())
{
auto t = q.front();
q.pop();
if (t == end) return d[t];
int distance = d[t];
int k = t.find('x');
int x = k / 3, y = k % 3; // 转化为横纵坐标
for (int i = 0; i < 4; i ++ )
{
int a = x + dx[i], b = y + dy[i];
if (a >= 0 && a < 3 && b >= 0 && b < 3)
{
swap(t[a * 3 + b], t[k]); // 状态更新
if (!d.count(t)) // 之前没有搜到过该状态
{
d[t] = distance + 1;
q.push(t); // 加入新状态
}
swap(t[a * 3 + b], t[k]); // 恢复状态
}
}
}
return -1;
}
int main()
{
char s[2];
string state;
for (int i = 0; i < 9; i ++ )
{
cin >> s;
state += *s;
}
cout << bfs(state) << endl;
return 0;
}- 多少个连通块:
- 遍历:BFS(
Flood-Fill算法)/DFS - 并查集
- 遍历:BFS(
- 多少个会被淹没:统计
total个点和bound个边界点
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#define x first
#define y second
using namespace std;
typedef pair<int, int> PII;
const int N = 1010;
int n;
char g[N][N];
bool st[N][N];
PII q[N * N];
int dx[4] = {-1, 0, 1, 0};
int dy[4] = {0, 1, 0, -1};
void bfs(int sx, int sy, int &total, int &bound)
{
int hh = 0, tt = 0;
q[0] = {sx, sy};
st[sx][sy] = true;
while (hh <= tt)
{
PII t = q[hh ++ ];
total ++ ;
bool is_bound = false;
for (int i = 0; i < 4; i ++ )
{
int x = t.x + dx[i], y = t.y + dy[i];
if (x < 0 || x >= n || y < 0 || y >= n) continue; // 出界
if (st[x][y]) continue;
if (g[x][y] == '.')
{
is_bound = true;
continue;
}
q[ ++ tt] = {x, y}; // 未遍历过并且是陆地
st[x][y] = true;
}
if (is_bound) bound ++ ;
}
}
int main()
{
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%s", g[i]);
int cnt = 0;
for (int i = 0; i < n; i ++ )
for (int j = 0; j < n; j ++ )
if (!st[i][j] && g[i][j] == '#') // 没搜过并且是岛屿
{
int total = 0, bound = 0;
bfs(i, j, total, bound); // Flood-Fill 算法
if (total == bound) cnt ++ ;
}
printf("%d\n", cnt);
return 0;
}1.3 图的存储方式与遍历
树是无环连通图,是一种特殊的图。图分为有向图和无向图。
- 邻接矩阵
- 邻接表:每个节点开了一个单链表,存储该节点可以到达的节点,每次在头节点位置插入
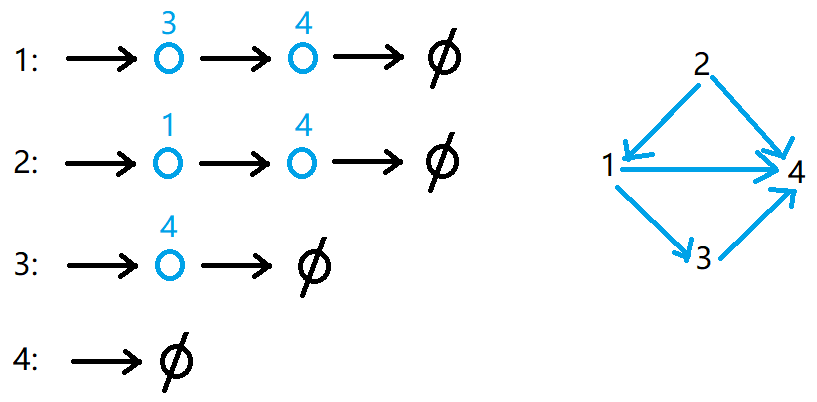
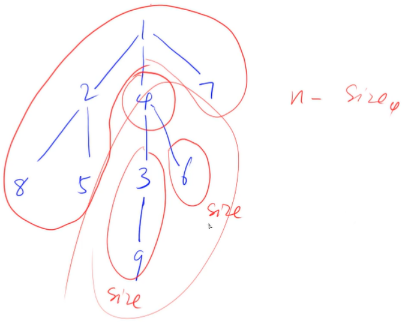
给定一棵树,树中包含 $n$ 个结点(编号 $1∼n$)和 $n − 1$ 条无向边。
请你找到树的重心,并输出将重心删除后,剩余各个连通块中点数的最大值。
重心定义:重心是指树中的一个结点,如果将这个点删除后,剩余各个连通块中点数的最大值最小,那么这个节点被称为树的重心。
输入格式
第一行包含整数 $n$,表示树的结点数。
接下来 $n − 1$ 行,每行包含两个整数 $a$ 和 $b$,表示点 $a$ 和点 $b$ 之间存在一条边。
输出格式
输出一个整数 $m$,表示将重心删除后,剩余各个连通块中点数的最大值。
数据范围
$1≤n≤10^5$
注意:
e[M],ne[M]的数组容量需设为M = N * 2,因为题目所述的图是无向图,最大可能会有N * 2条边。若不这样设,将会TLE;ans初始值应设置为N(最大值),否则一直输出结果都是0.
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 100010, M = N * 2;
int h[N], e[M], ne[M]; // h数组存储每个链表的链表头,e数组存储每个节点的编号,ne存储的是每个节点的next指针
int n, idx;
bool st[N]; // 标记是否已经被访问
int ans = N; // 记录答案
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
// 以u为根的子树中点的数量
int dfs(int u)
{
st[u] = true; // 标记一下, 已经被搜过
int sum = 1, res = 0; // sum记录当前子树的点, res记录当前子树的连通块点数
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
int s = dfs(j); // 获得子树连通块点的数量
res = max(res, s); // 将s与res取大
sum += s; // 将子树的数量加入m点数
}
}
res = max(res, n - sum); // n - sum为除了以该点为子树的剩余部分
ans = min(ans, res); // 记录结果
return sum; // 返回子树数量
}
int main()
{
cin >> n;
memset(h, -1, sizeof h);
for (int i = 0; i < n - 1; i++)
{
int a, b;
cin >> a >> b;
add(a, b), add(b, a); // 无向边, 需要添加不同方向的两条边
}
dfs(1); // 从任意节点开始深度优先
cout << ans << endl;
return 0;
}给定一个 $n$ 个点、$m$ 条边的有向图,图中可能存在重边和自环,所有边的长度都是 $1$,点的编号为 $1\sim n$。
求出 $1$ 号点到 $n$ 号点的最短距离,若从 $1$ 号点无法走到 $n$ 号点,输出 $−1$。
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 100010;
int h[N], e[N], ne[N], idx, n, m;
int d[N], q[N]; // d数组记录最远距离, q数组记录队列
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
int bfs()
{
int hh = 0, tt = 0;
q[0] = 1; // 初始化
memset(d, -1, sizeof d);
d[1] = 0;
while (hh <= tt)
{
int t = q[hh++];
for (int i = h[t]; i != -1; i = ne[i]) // 扩展每个点的邻边
{
int j = e[i];
if (d[j] == -1) // 第一次被访问
{
d[j] = d[t] + 1;
q[++tt] = j;
}
}
}
return d[n];
}
int main()
{
cin >> n >> m;
memset(h, -1, sizeof h);
for (int i = 0; i < m; i++)
{
int a, b;
cin >> a >> b;
add(a, b);
}
cout << bfs() << endl;
return 0;
}1.4 有向图的拓扑序列
若一个由图中所有点构成的序列A满足:对于图中的每条边 (x,y),x在A中都出现在y之前,则称A是该图的一个拓扑序列。
若有环,所有点的入度都非 $0$,找不到突破口,故非拓扑序列。
有向无环图称为拓扑图。
queue <- 所有入度为0的点
while queue不为空:
{
t <- 队头
枚举 t 的所有出边 t -> j
删去t -> j, d[j]--;
if d[j] == 0:
queue <- j;
}#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
int n, m;
int h[N], e[N], ne[N], idx;
int d[N]; // 存储节点的入度
int q[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
bool topsort()
{
int hh = 0, tt = -1;
for (int i = 1; i <= n; i ++ )
if (!d[i])
q[ ++ tt] = i; // 将所有入度为0的点加到队列中去
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (-- d[j] == 0)
q[ ++ tt] = j;
}
}
return tt == n - 1; // 所有点都进入队列,是拓扑序列
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
for (int i = 0; i < m; i ++ )
{
int a, b;
scanf("%d%d", &a, &b);
add(a, b);
d[b] ++ ;
}
if (!topsort()) puts("-1");
else
{
for (int i = 0; i < n; i ++ ) printf("%d ", q[i]);
puts("");
}
return 0;
}1.5 二叉树的遍历
一个二叉树,树中每个节点的权值互不相同。现在给出它的后序遍历和中序遍历,请你输出它的层序遍历。
输入样例:
7
2 3 1 5 7 6 4
1 2 3 4 5 6 7输出样例:
4 1 6 3 5 7 2实现:
- 先在后序遍历找到根节点,再到中序遍历找到根节点在哪出现,中序遍历根节点的左边是左子树,右边是右子树
- 递归建左子树,返回左子树的根节点,插在根节点的左儿子上,同理处理右子树
- 从根节点
bfs一遍
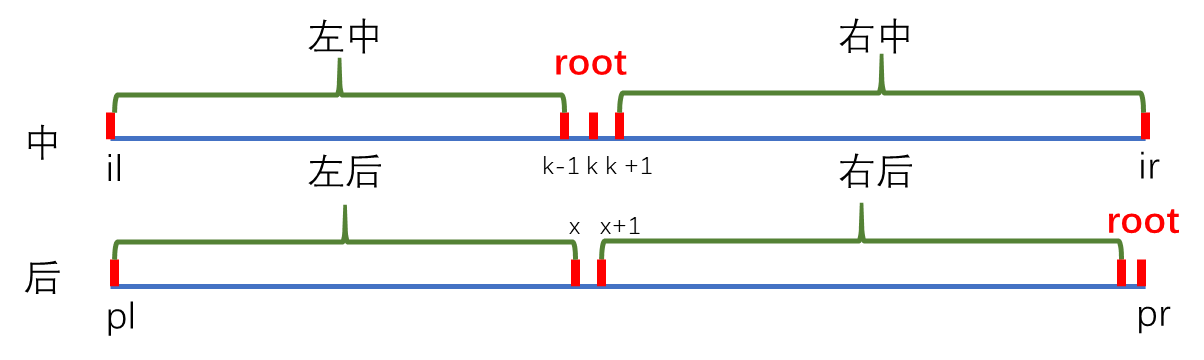
由左子树的中序遍历序列等于左子树的后序遍历序列,有 $x-pl=k-1-il$,则 $x=pl+k-1-il$
优化:找一个节点在中序遍历里的第几个位置出现,用 hash 表存对应的左儿子、右儿子和下标
#include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_map>
using namespace std;
const int N = 40;
int n;
int q[N];
int postorder[N], inorder[N]; // 后序遍历和中序遍历序列
unordered_map<int, int> l, r, pos;
int build(int il, int ir, int pl, int pr) // 中序遍历和后序遍历的区间
{
int root = postorder[pr]; // 根节点的位置
int k = pos[root]; // 在中序遍历中根节点的下标
// 判断左、右子树是否存在
if (il < k) l[root] = build(il, k - 1, pl, pl + k - 1 - il);
if (ir > k) r[root] = build(k + 1, ir, pl + k - 1 - il + 1, pr - 1);
return root;
}
void bfs(int root)
{
int hh = 0, tt = -1;
q[ ++ tt] = root;
while(hh <= tt)
{
auto t = q[hh ++ ];
cout << t << ' ';
if (l.count(t)) q[ ++ tt] = l[t];
if (r.count(t)) q[ ++ tt] = r[t];
}
}
int main()
{
cin >> n;
for (int i = 0; i < n; i ++ ) cin >> postorder[i];
for (int i = 0; i < n; i ++ )
{
cin >> inorder[i];
pos[inorder[i]] = i; // 记录中序遍历的下标
}
int root = build(0, n - 1, 0, n - 1);
bfs(root);
return 0;
}二叉搜索树的中序遍历是有序的,只需将输入的数组进行升序排列即可得到中序遍历序列。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 110;
int n, l[N], r[N], w[N], q[N];
int a[N];
void dfs(int u, int& k)
{
if(u == -1) return ;
else
{
dfs(l[u], k);
w[u] = a[k++];
dfs(r[u], k);
}
}
void bfs()
{
int hh = 0, tt = 0;
q[0] = 0;
while(hh <= tt)
{
int t = q[hh++];
if(l[t] != -1) q[++tt] = l[t];
if(r[t] != -1) q[++tt] = r[t];
printf("%d ",w[t]);
}
}
int main()
{
scanf("%d", &n);
for(int i = 0; i < n; i ++ )
scanf("%d%d", &l[i], &r[i]);
for(int i = 0; i < n; i ++ )
scanf("%d", &a[i]);
sort(a, a + n);
int k = 0;
dfs(0, k);
bfs();
return 0;
}二、最短路径问题
[注意算法的时间复杂度]
单源最短路径
- 所有边权都是正数
- 朴素
Dijkstra算法 $O(n^2)$ 边稠密图m~n^2(一个等级) - 堆优化版的
Dijkstra算法 $O(mlogn)$ 边稀疏图m~n
- 朴素
- ==存在负权边==
Bellman-Ford算法 $O(nm)$ 求不超过 $k$ 条边SPFA算法 一般 $O(m)$,最坏 $O(nm)$
多源汇最短路径(起点、终点任选)
Floyd算法 $O(n^3)$
2.1 朴素Dijkstra算法
dist[1]=0,dist[i]=+∞,s为当前已确定最短路径的点for i: 0 ~ nt<-不在s中的、距离最近的点s<-t,用t更新其他点的距离,dist[x] > dist[t] + w
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 510;
int n, m;
int g[N][N];
int dist[N];
bool st[N];
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 初始化
for (int i = 0; i < n; i++)
{
int t = -1; // t为-1表示还未选择一个点
for (int j = 1; j <= n; j++)
{
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j; // 选取还未被选择的且距离最近的点
}
st[t] = true;
for (int j = 1; j <= n; j++)
{
dist[j] = min(dist[j], dist[t] + g[t][j]);
}
}
if (dist[n] == 0x3f3f3f3f) return -1; // 不连通
return dist[n];
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m--)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
g[a][b] = min(g[a][b], c);
}
int t = dijkstra();
printf("%d\n", t);
return 0;
}2.2 堆优化版的Dijkstra算法
用堆来找不在 $S$ 中的、距离最近的点。堆有两种实现形式:
- 手写堆(n个数)
- 优先队列(m个数)—> 每次更新距离将距离最近的点放入堆中,可能有冗余备份
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e6 + 10;
int n, m;
int h[N], w[N], e[N], ne[N], idx;
int dist[N];
bool st[N];
void add(int a, int b, int c)
{
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++ ;
}
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap; // 小根堆
heap.push({0, 1});
while (heap.size())
{
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if (st[ver]) continue; // 被更新过,是冗余备份
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[ver] + w[i])
{
dist[j] = dist[ver] + w[i];
heap.push({dist[j], j});
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h); // 表头初始化为空节点
while (m -- )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
add(a, b, c);
}
cout << dijkstra() << endl;
return 0;
}2.3 Bellman-Ford算法
for n次
备份数组 // 不超过k条边时, 保证不发生串联
for 所有边 a,b,w (存在一条从a到b的边,权重为w)
dist[b] = min(dist[b], dist[a] + w); // 松弛操作迭代完成后,有三角不等式:dist[b] <= dist[a] + w。
k次—>经过不超过k条边的最短路径的距离
n次—>存在一条最短路径,上面有n条边,则路径上一定存在负环
算法时间复杂度为 $O(nm)$,$n$ 表示点数,$m$ 表示边数。
注意在模板题中需要对下面的模板稍作修改,加上备份数组,详情见模板题。
int n, m; // n表示点数,m表示边数
int dist[N]; // dist[x]存储1到x的最短路距离
struct Edge // 边,a表示出点,b表示入点,w表示边的权重
{
int a, b, w;
}edges[M];
// 求1到n的最短路距离,如果无法从1走到n,则返回-1。
int bellman_ford()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 如果第n次迭代仍然会松弛三角不等式,就说明存在一条长度是n + 1的最短路径,由抽屉原理,路径中至少存在两个相同的点,说明图中存在负权回路。
for (int i = 0; i < n; i ++ )
{
for (int j = 0; j < m; j ++ )
{
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
if (dist[b] > dist[a] + w)
dist[b] = dist[a] + w;
}
}
if (dist[n] > 0x3f3f3f3f / 2) return -1;
return dist[n];
}注:
由于需要限制
k条边,为了避免先更新b,再用b去更新别的结果,以保证只用上一次迭代的结果,则先备份数组。
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 510, M = 10010;
struct Edge
{
int a, b, c;
}edges[M];
int n, m, k;
int dist[N];
int last[N]; //用于备份
void bellman_ford()
{
memset(dist, 0x3f, sizeof dist); //初始化
dist[1] = 0;
for (int i = 0; i < k; i++)
{
memcpy(last, dist, sizeof dist); //将当前的值赋值到last数组中来备份
for (int j = 0; j < m; j++)
{
auto e = edges[j];
dist[e.b] = min(dist[e.b], last[e.a] + e.c); //取最小值
}
}
}
int main()
{
scanf("%d%d%d", &n, &m, &k);
for (int i = 0; i < m; i++)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
edges[i] = { a, b, c };
}
bellman_ford();
//除以2的原因是0x3f3f3f3f也可能经历一些小的改变
if (dist[n] > 0x3f3f3f3f / 2) puts("impossible");
else printf("%d\n", dist[n]);
return 0;
}2.4 SPFA算法
考虑到dist[e.b] = min(dist[e.b], last[e.a] + e.c);一式只有当a变化的时候dist[e.b]才会发生改变,故有:
while queue 不空
(1) t <- q.front;
q.pop();
(2) 更新t的所有出边: t -w-> b; //待更新的点的集合
queue <- b即:我更新过谁,我后面的人才会变小。
2.4.1 SPFA算法求最短路径
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 100010;
int n, m;
int h[N], w[N], e[N], ne[N], idx;
int dist[N];
bool st[N];
void add(int a, int b, int c)
{
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx++;
}
int spfa()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);
st[1] = true; // 存储当前点是否在队列中
while (q.size())
{
int t = q.front(); // 将队首元素取出
q.pop();
st[t] = false; // 设为false代表已经出队
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if (!st[j])
{
// 如果不在队列里,将其入队
q.push(j);
st[j] = true;
}
}
}
}
return dist[n];
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
while (m--)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
add(a, b, c);
}
int t = spfa();
if (t == 0x3f3f3f3f) puts("impossible");
else printf("%d\n", t);
return 0;
}注:网格图容易卡
SPFA算法。
本题存在三个变量,横坐标 $x$、纵坐标 $y$、状态 $s$,可以转换为单源最短路径问题,状态之间的转移关系 $(x,y,s)\rightarrow (x’,y’,s’)$,其中 $s’=s*w(x,y);mod;4+1$。
注:此题无法用
DP做,DP实际上是有向无环图上的最短路问题。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 6;
int w[N][N];
int sx, sy, tx, ty;
int dist[N][N][5];
bool st[N][N][5];
struct Node
{
int x, y, s;
};
int spfa()
{
queue<Node> q;
q.push({sx, sy, 1});
memset(dist, 0x3f, sizeof dist);
dist[sx][sy][1] = 0;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
while (q.size())
{
auto t = q.front();
q.pop();
st[t.x][t.y][t.s] = false;
for (int i = 0; i < 4; i ++ )
{
int x = t.x + dx[i], y = t.y + dy[i];
if (x < 0 || x >= N || y < 0 || y >= N) continue;
int cost = t.s * w[x][y];
int s = cost % 4 + 1;
if (dist[x][y][s] > dist[t.x][t.y][t.s] + cost)
{
dist[x][y][s] = dist[t.x][t.y][t.s] + cost;
if (!st[x][y][s])
{
q.push({x, y, s});
st[x][y][s] = true;
}
}
}
}
int res = 1e8;
for (int i = 1; i <= 4; i ++ )
res = min(res, dist[tx][ty][i]);
return res;
}
int main()
{
for (int i = 0; i < N; i ++ )
for (int j = 0; j < N; j ++ )
scanf("%d", &w[i][j]);
scanf("%d%d%d%d", &sx, &sy, &tx, &ty);
printf("%d\n", spfa());
return 0;
}2.4.2 SPFA算法判断负环
dist[x]表示1 ~ x的最短距离,cnt[x]表示1 ~ x经过的边数,有:dist[x] = dist[t] + w[i]; cnt[x] = cnt[t] + 1,若有cnt[x] >= n,则在这个路径上有n + 1个点(n条边),由抽屉原理可知,存在有两个相同的点(先走到i,过一段时间又回到i),该路径存在负环。
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 2010, M = 10010;
int n, m;
int h[N], w[M], e[M], ne[M], idx;
int dist[N], cnt[N];
bool st[N];
void add(int a, int b, int c)
{
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++ ;
}
bool spfa()
{
queue<int> q;
for (int i = 1; i <= n; i ++ )
{
st[i] = true;
q.push(i);
}
while (q.size())
{
int t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1;
if (cnt[j] >= n) return true;
if (!st[j])
{
q.push(j);
st[j] = true;
}
}
}
}
return false;
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
while (m -- )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
add(a, b, c);
}
if (spfa()) puts("Yes");
else puts("No");
return 0;
}2.5 Floyd算法
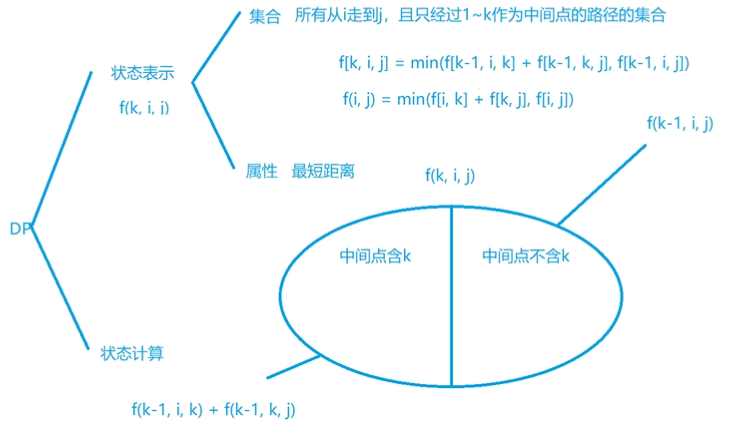
Floyd 算法基于动态规划,状态表示 d[k, i, j] 的含义是从 i 点,只经过 1 到 k 这些中间点,到达 j 点的最短路径,利用 d[k, i, j] = d[k - 1, i, k] + d[k - 1, k, j] 方程进行状态更新。
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 210, INF = 1e9;
int n, m, Q;
int d[N][N];
void floyd()
{
for (int k = 1; k <= n; k ++ )
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
int main()
{
scanf("%d%d%d", &n, &m, &Q);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
while (m -- )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
d[a][b] = min(d[a][b], c);
}
floyd();
while (Q -- )
{
int a, b;
scanf("%d%d", &a, &b);
int t = d[a][b];
if (t > INF / 2) puts("impossible");
else printf("%d\n", t);
}
return 0;
}给定一张带权无向完全图,设点的编号为 $1,2,3,4,5,…,n$(以邻接矩阵的形式给出)。
计算依次拿走第 $i$ 个点后,剩余所有点到其他点的最短距离之和的总和。
将 Floyd 算法逆序,先把 $n$ 号点扩进来,$n-1$,…
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
int n;
int d[N][N];
int main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
scanf("%d", &d[i][j]);
int res = 0;
for (int k = n; k > 1; k -- )
for (int i = 1; i <= n; i ++ )
for (int j = i + 1; j <= n; j ++ )
{
if (d[i][j] > d[i][k] + d[k][j])
d[i][j] = d[j][i] = d[i][k] + d[k][j]; // 比 min 要快一些
if (i >= k && j >= k) res += d[i][j] * 2; // 对称, 可以只枚举一半
}
printf("%d\n", res);
return 0;
}三、最小生成树问题
对于带权连通无向图 $G=(V,E)$,生成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。设 $R$ 为 $G$ 的所有生成树的集合,若 $T$ 为 $R$ 中边的权值之和最小的生成树,则 $T$ 称为 $G$ 的最小生成树(MST)。
3.1 Prim算法
朴素版Prim:算法时间复杂度为 $O(n^{2})$,适用于稠密图。
dist[i] <- +∞ // dist数组表示该点到集合的距离, 而非起点距离
for (i = 0; i < n; i++)
t <- 找到集合外距离最近的点
用 t 更新其他点到集合的距离 // 与迪杰斯特拉算法不一样
st[t] = true;#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n, m;
int g[N][N];
int dist[N];
bool st[N];
int prim()
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
for (int i = 0; i < n; i ++ ) // 遍历n个点
{
int t = -1; // 初始化为未找到点
for (int j = 1; j <= n; j ++ )
{
// t == -1 表示当前未找到任何点
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
}
// 不是第一个取出的节点,并且当前节点的距离为INF,表示没有和集合中点相连的边
if (i && dist[t] == INF) return INF;
// 不是第一个取出的顶点,是其他点与集合中的连接线(最小边),注1
if (i) res += dist[t];
st[t] = true; // 加入到生成树中
// 用当前最短边权点t更新其他点到集合的距离
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
g[a][b] = g[b][a] = min(g[a][b], c); // 无向图
}
int t = prim();
if (t == INF) puts("impossible"); // 所有点不连通
else printf("%d\n", t);
return 0;
}注:
[1]如果一个节点本身出现负环,
dist[j] = min(dist[j], g[t][j])更新后,会影响res结果,需后执行。即g[t][j], 当t == j,更新了g[t][t],会影响res结果。比如
4->4 -10,更新后dist[4] = min(dist[4], g[4][4])。[2]堆优化版
Prim的时间复杂度为$O(mlogn)$,在实际中可以使用Kruskal算法。
3.2 Kruskal算法
算法时间复杂度为 $O(mlogn)$,适用于稀疏图。
- 将所有边按权重从小到大排序(调用
sort函数,是该算法的瓶颈) - 枚举每条边
a - b,权重是c,如果a - b不连通,将这条边加入集合中去—>并查集
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010, M = 200010, INF = 0x3f3f3f3f;
int n, m;
int p[N];
struct Edge
{
int a, b, w;
bool operator< (const Edge &W)const
{
return w < W.w;
}
}edges[M];
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m); // 将边的权重按照大小排序
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0; // res记录最小生成树的边权重之和,cnt记录全部加入到树的集合中边的数量
for (int i = 0; i < m; i ++ )
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
// 查找a和b是否在一个集合中
a = find(a), b = find(b);
// 若在一个集合中,如果a和b已经在一个集合当中了,说明这两个点已经被一种方式连接起来了;如果加入a - b这条边,会导致集合中有环的生成
if (a != b)
{
p[a] = b; // 将两个集合连接起来
res += w; // 加入到集合中的边权重之和
cnt ++ ; // 集合的边数+1
}
}
if (cnt < n - 1) return INF; // 无法生成最小生成树
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
int a, b, w;
scanf("%d%d%d", &a, &b, &w);
edges[i] = {a, b, w};
}
int t = kruskal();
if (t == INF) puts("impossible");
else printf("%d\n", t);
return 0;
}四、二分图
将所有点分成两个集合,使得所有边只出现在集合之间,就是二分图;
二分图中一定不含有奇数环,可能包含长度为偶数的环, 不一定是连通图。
一个图是二分图,当且仅当图中不含有奇数环。
4.1 二分图的判别:染色法
算法时间复杂度为 $O(n+m)$
for(i = 1; i <= n; i++)
if i未染色
dfs(i, 1) // 1代表染成1号颜色#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010, M = 200010;
int n, m;
int h[N], e[M], ne[M], idx;
int color[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
bool dfs(int u, int c)
{
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (!color[j]) // 未被染色
{
if (!dfs(j, 3 - c)) return false;
}
else if (color[j] == c) // 判断是否冲突
return false;
}
return true;
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
while (m -- )
{
int a, b;
scanf("%d%d", &a, &b);
add(a, b), add(b, a);
}
bool flag = true;
for (int i = 1; i <= n; i ++ )
if (!color[i])
{
if (!dfs(i, 1)) // 对连通图进行深度优先
{
flag = false;
break;
}
}
if (flag) puts("Yes");
else puts("No");
return 0;
}变式:关押罪犯
4.2 二分图的最大匹配:匈牙利算法
二分图的匹配:给定一个二分图 $G$,在 $G$ 的一个子图中,$M$ 的边集 ${E}$ 中的任意两条边都不依附于同一个顶点,则称$M$是一个匹配。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
匈牙利算法的时间复杂度为 $O(mn)$,实际运行时间一般远小于 $O(mn)$。
其算法原理可理解为“男女匹配”算法,匈牙利算法的核心就是不停的寻找增广路径来扩充匹配集合M。
要点:
- 匈牙利算法中,一个有伴侣的人,无论男女,不会重新变成单身狗
- 若我们尝试给一个有对象的女生换个对象,如果成功,整个交换链终止于一个单身女性
状态:
st数组表示在该轮模拟匹配中女生是否被预定match数组表示女生是否已经被男生匹配
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 510, M = 100010;
int n1, n2, m; // 有 n1 个男生和 n2 个女生,他们之间可以匹配的关系有 m 个
int h[N], e[M], ne[M], idx;
int match[N]; // match[a] = b 说明 女生 a 目前匹配了男生 b
bool st[N]; // st[a] = true 说明 女生 a 目前被一个男生预定了(不被别的男生考虑)
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
// 用来判断若加入x来参与模拟配对,会不会使匹配数增多
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i]) // 看上妹子的集合
{
int j = e[i];
if (!st[j]) // 之前没有考虑过,即在这一轮模拟匹配中,这个女孩尚未被预定
{
st[j] = true;
if (match[j] == 0 || find(match[j])) // 妹子没有匹配任何男生, 或可以为男生找到下家
{
match[j] = x; // 为女生匹配该男生
return true;
}
}
}
return false;
}
int main()
{
scanf("%d%d%d", &n1, &n2, &m);
memset(h, -1, sizeof h);
while (m -- )
{
int a, b;
scanf("%d%d", &a, &b);
add(a, b);
}
int res = 0;
for (int i = 1; i <= n1; i ++ )
{
memset(st, false, sizeof st); // 每轮将st数组置为false
if (find(i)) res ++ ;
}
printf("%d\n", res);
return 0;
}变式:棋盘覆盖
五、欧拉回路
判断是否为无向图的条件:
- 所有点的度数必须是奇数
- 所有边连通
判断是否为有向图的条件:
- 所有点的入度等于出度
- 所有边连通
给定一张图,请你找出欧拉回路,即在图中找一个环使得每条边都在环上出现恰好一次。
输入格式如下:
第一行包含一个整数 $t$,$t∈{1,2}$,如果 $t=1$,表示所给图为无向图,如果 $t=2$,表示所给图为有向图。
第二行包含两个整数 $n,m$,表示图的结点数和边数。
接下来 $m$ 行中,第 $i$ 行两个整数 $v_i,u_i$,表示第 $i$ 条边(从 $1$ 开始编号)。
- 如果 $t=1$ 则表示 $v_i$ 到 $u_i$ 有一条无向边。
- 如果 $t=2$ 则表示 $v_i$ 到 $u_i$ 有一条有向边。
图中可能有重边也可能有自环,点的编号从 $1$ 到 $n$。
#include<bits/stdc++.h>
using namespace std;
#define N 100020
#define M 200020
#define INF 0x3f3f3f3f
int n, m, type, cnt, ans[M];
bool used[2 * M];
int in[N], out[N]; // din 数组用于记录每个节点的入度,dout 数组用于记录每个节点的出度
int h[N], e[2 * M], ne[2 * M], idx;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
void dfs(int u)
{
for (int i = h[u]; i != -1; i = h[u]) // 枚举所有出边
{
if (used[i])
{
h[u] = ne[i];
continue;
}
used[i] = true;
if (type == 1) used[i ^ 1] = true; //若为无向图,则将反向边判重(异或标记即将末位取反,0^1=1, 1^1=0)
h[u] = ne[i];
dfs(e[i]);
if (type == 1) {
if (i % 2) ans[++cnt] = -(i + 1) / 2;
else ans[++cnt] = (i + 2) / 2;
}
else ans[++cnt] = i + 1;
}
}
int main()
{
memset(h, -1, sizeof h);
scanf("%d", &type);
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i++) {
int a, b;
scanf("%d%d", &a, &b);
add(a, b); in[b]++, out[a]++;
if (type == 1) add(b, a);
}
if (type == 1) { //无向图需保证每个点的度为偶数
for (int i = 1; i <= n; i++) {
if ((in[i] + out[i]) % 2) {
printf("NO\n"); return 0;
}
}
}
else {//有向图需保证每个点的出度与入度相等
for (int i = 1; i <= n; i++) {
if (in[i] != out[i]) {
printf("NO\n"); return 0;
}
}
}
//防止在单独孤立的点上求bfs
for (int i = 1; i <= n; i++)
if (h[i] != -1) {
dfs(i);
break;
}
//判断边是否连通
if (cnt != m) {
printf("NO\n");
return 0;
}
printf("YES\n");
//逆序输出序列
for (int i = cnt; i; i--)
printf("%d ", ans[i]);
return 0;
}
