一、Numpy介绍
- 一个开源的
python科学计算库 - 使用
Numpy可以方便的使用数组、矩阵进行计算 - 包含线性代数、傅里叶变换、随机数生成等大量函数
二、ndarray结构基础知识
对于ndarray结构来说,里面所有的元素必须是同一类型的;若不是,会自动的向下进行转换。
2.1 ndarray的属性
import numpy as np
tang_list = [1,2,3,4,5]
tang_array = np.array(tang_list)
tang_array #array([1, 2, 3, 4, 5])
type(tang_array) #numpy.ndarray
tang_array.itemsize #4,表示占4个字节
tang_array.shape #(5,)
tang_array.size #52.2 索引与切片
与Python数据结构的语法是一样的。
tang_array[1:3] #array([2, 3])
tang_array[-2:] #array([4, 5])2.3 矩阵形式
tang_array = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
tang_array.shape #(3, 3)
tang_array.size #9
tang_array.ndim #2
tang_array[1,1] #5
tang_array[1,1] = 10
tang_array #array([[ 1, 2, 3],
#[ 4, 10, 6],
#[ 7, 8, 9]])
tang_array[:,1] #array([2,5,8])
tang_array[0,0:2] #array([1,2])注意:
tang_array2 = tang_array操作与Java对象名的引用性质类似,该语句将tang_array2直接指向tang_array的内存位置,当操纵tang_array2,tang_array将发生变动。- 若希望两个变量互不干扰,应为:
tang_array2 = tang_array.copy()
2.4 布尔类型作为索引
arange函数将构造等差数列的数组:【1.6节将介绍】
tang_array = np.arange(0,100,10)
tang_array #array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])布尔类型作为索引,取值根据true和false来判断。
mask = np.array([0,0,0,1,1,1,0,0,1,1],dtype = bool)
mask #array([False, False, False, True, True, True, False, False, True, True])
tang_array[mask] #array([30, 40, 50, 80, 90])利用条件保留数据:
mask = random_array > 0.5
mask #array([ True, True, True, False, True, False, False, True, False, True])
tang_array[mask] #array([ 0, 10, 20, 40, 70, 90])返回索引值并得到数据:
tang_array = np.array([10,20,30,40,50])
tang_array > 30 #array([False, False, False, True, True])
np.where(tang_array > 30) #(array([3, 4], dtype=int64),)
tang_array[np.where(tang_array > 30)] #array([40, 50])2.5 数组类型
tang_array = np.array([1,2,3,4,5],dtype = np.float32)
tang_array #array([1., 2., 3., 4., 5.], dtype=float32)
tang_array.nbytes #20,占用的字节数4*5注:
可以指定任意类型,即
object类型:tang_array = np.array([1,10,3.5,'str'],dtype = np.object) tang_array #array([1, 10, 3.5, 'str'], dtype=object)但不利于计算。
转换类型:
asarray方法和astype方法可以获得一个新的转换类型后的结构,但不会改变原始ndarray结构:
tang_array = np.array([1,2,3,4,5])
tang_array2 = np.asarray(tang_array,dtype=np.float32) #array([1., 2., 3., 4., 5.], dtype=float32)
tang_array.astype(np.float32) #array([1., 2., 3., 4., 5.], dtype=float32)三、array数组的数值计算
3.1 按维度累加与累乘
axis参数指定要进行的操作是**沿着什么轴(维度)**计算结果。
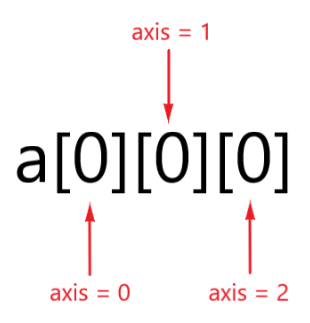
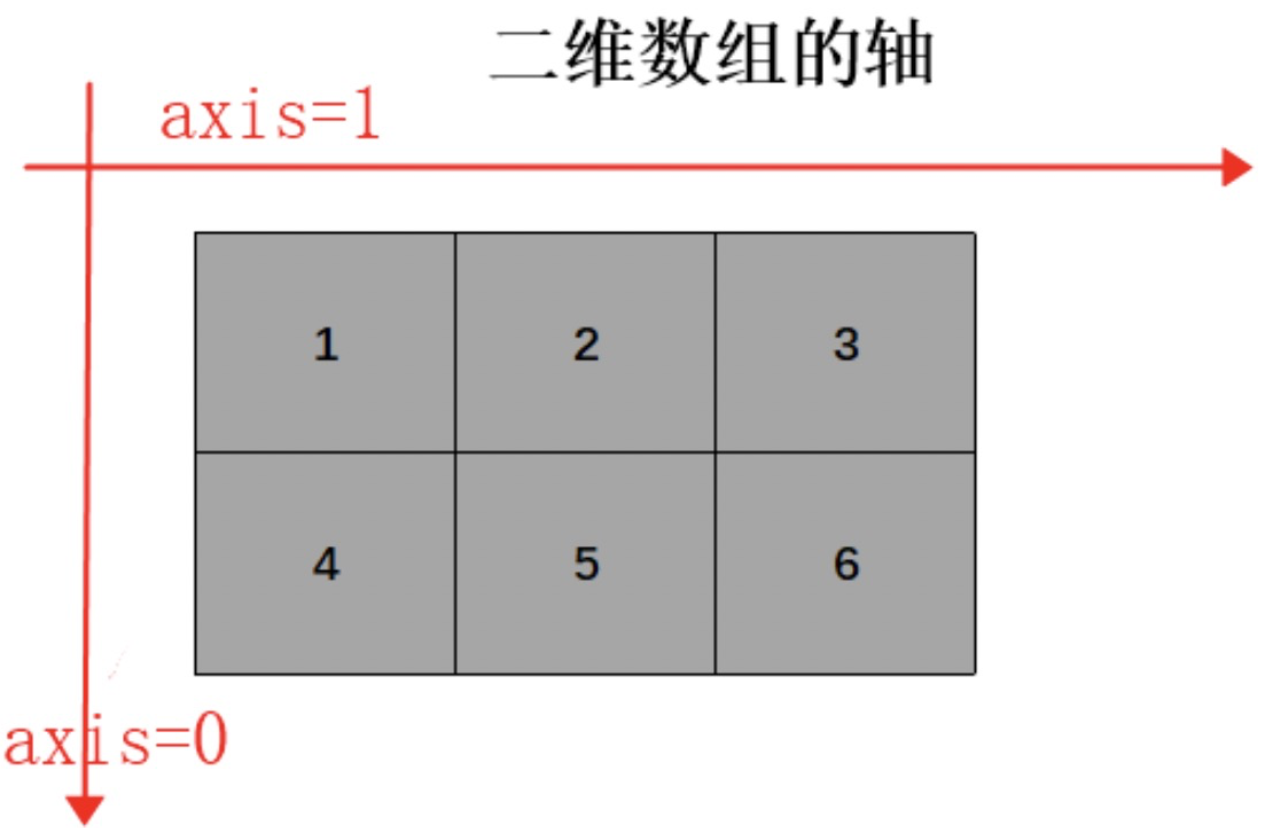
累加:
tang_array = np.array([[1,2,3],[4,5,6]])
np.sum(tang_array,axis = 0) #array([5, 7, 9]),沿着第一个轴
np.sum(tang_array,axis = 1) #array([ 6, 15]),沿着第二个轴
np.sum(tang_array,axis = -1) #array([ 6, 15]),沿着第二个轴累乘:
tang_array.prod() #720,所有数的乘积
tang_array.prod(axis = 1) #array([ 6, 120])3.2 求最小/最大/均值/标准差/方差
tang_array.min(axis = 0) #array([1, 2, 3])
tang_array.argmin() #0,最小值的索引值
tang_array.argmin(axis = 0) #array([0, 0, 0], dtype=int64)
tang_array.argmax() #5
tang_array.mean() #3.5,均值
tang_array.mean(axis = 0) #array([2.5, 3.5, 4.5])
tang_array.std() #1.707825127659933,标准差
tang_array.var() #2.91666666666666653.3 作限制
把数据限制到某个范围内。
tang_array.clip(2,4) #array([[2, 2, 3],[4, 4, 4]])
tang_array = np.array([1.2,3.56,6.41]) #array([1., 4., 6.]),四舍五入
tang_array.round(decimals = 1) #array([1.2, 3.6, 6.4]),对第一个小数进行四舍五入,指定精度四、排序
4.1 基本排序
tang_array = np.array([[1.5,1.3,7.5],[5.6,7.8,1.2]])
np.sort(tang_array) #array([[1.3, 1.5, 7.5],[1.2, 5.6, 7.8]])
np.sort(tang_array,axis = 0) #array([[1.5, 1.3, 1.2],[5.6, 7.8, 7.5]])
np.argsort(tang_array) #array([[1, 0, 2],[2, 0, 1]], dtype=int64),返回排序位置原先的索引位置tang_array = np.linspace(0,10,10) #按照平均差异构造十个数
#array([ 0. , 1.11111111, 2.22222222, 3.33333333, 4.44444444,
# 5.55555556, 6.66666667, 7.77777778, 8.88888889, 10. ])
values = np.array([2.5,6.5,9.5]) #不知道要插入到什么样的位置
np.searchsorted(tang_array,values) #array([3, 6, 9], dtype=int64),必须是一个排序好的结构4.2 分开指定进行排序
tang_array = np.array([[1,0,6],[1,7,0],[2,3,1],[2,4,0]])
index = np.lexsort([-1*tang_array[:,0],tang_array[:,2]]) #array([3, 1, 2, 0], dtype=int64)
#按第2列进行升序条件下按照第0列进行降序
tang_array = tang_array[index] #array([[2, 4, 0],[1, 7, 0],[2, 3, 1],[1, 0, 6]])五、数组形状操作
数组的形状操作需保证数组大小必须不能改变。
tang_array = np.arange(10)
tang_array.shape #(10,)
tang_array.shape = 2,5 #array([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])5.1 更改维度
tang_array = np.arange(10)
tang_array.shape #(10,)
tang_array = tang_array[np.newaxis,:]
tang_array #array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
tang_array.shape #(1, 10)
tang_array = tang_array[:,np.newaxis]
tang_array.shape #(10, 1)
tang_array = tang_array[:,np.newaxis,np.newaxis]
tang_array.shape #(10, 1, 1, 1)
tang_array = tang_array.squeeze() #压缩
tang_array.shape #(10,)5.2 转置操作
tang_array.shape = 2,5
tang_array.transpose() #array([[0, 5],[1, 6],[2, 7],[3, 8],[4, 9]]),转置操作
tang_array.T #转置操作5.3 数组的连接
a = np.array([[123,456,678],[3214,456,134]])
b = np.array([[1235,3124,432],[43,13,134]])
c = np.concatenate((a,b)) #array([[123,456,678],[3214,456,134],[1235, 3124,432],[43,13,134]])
c = np.concatenate((a,b),axis = 1) #两行六列,array([[123,456,678,1235,3124,432],[3214,456,134,43,13,134]])
np.vstack((a,b)) #相当于axis = 0
np.hstack((a,b)) #相当于axis = 15.4 拉平操作
使用函数a.flatten()或a.ravel(),得到一长条。
六、数组生成函数
6.1 arange函数
np.arange(10):生成array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])np.arange(2,20,2):生成array([2,4,6,8,10,12,14,16,18])还可以指定
dtype值
6.2 linspace函数
np.linspace(0,10,10):在0到10之间构造10个数,包含头尾。
array([ 0. , 1.11111111, 2.22222222, 3.33333333, 4.44444444,
5.55555556, 6.66666667, 7.77777778, 8.88888889, 10. ])6.3 logspace函数
np.logspace(a,b,n):生成从10的a次方到10的b次方之间按对数等分的n个元素的行向量。n如果省略,则默认值为50。
如,np.logspace(1,5,5)的结果为array([1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05])
6.4 meshgrid函数
meshgrid函数可以构造网格,在使用立体索引时会用到。
x = np.linspace(-10,10,5)
y = np.linspace(-10,10,5)x为:
array([[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.]])y为:
array([[-10., -10., -10., -10., -10.],
[ -5., -5., -5., -5., -5.],
[ 0., 0., 0., 0., 0.],
[ 5., 5., 5., 5., 5.],
[ 10., 10., 10., 10., 10.]])6.5 构造行/列向量
np.r_[0:10:1]用于构造行向量:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])np.c_[0:10:1]用于构造列向量:
array([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9]])6.6 常用生成函数
6.6.1 生成相同值的矩阵
zeros函数:【经常用于初始化】
np.zeros(3) #array([0., 0., 0.])
np.zeros((3,3)) #array([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]]),第二个参数为维度ones函数:
np.ones((3,3))结果是:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])构造一个值为x的,在后面直接*x即可。如:np.ones((3,3)) * 8,将生成值全为8的矩阵。
zeros_like函数:返回相同形状的全零矩阵【复制维度】
np.zeros_like(tang_array)结果是array([0,0,0,0])。
同理,还有
ones_like函数。
6.6.2 生成单位矩阵
np.identity(5)结果为:
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])七、相关运算
7.1 乘法
直接相乘:【对应位置进行相乘】
x = np.array([5,5])
y = np.array([2,2])
np.multiply(x,y) #array([10, 10])矩阵相乘:【需确保矩阵相乘规则】
注:矩阵相乘的规则:
一个
m*n的矩阵和一个n*p的矩阵相乘,将会得到一个m*p的矩阵。
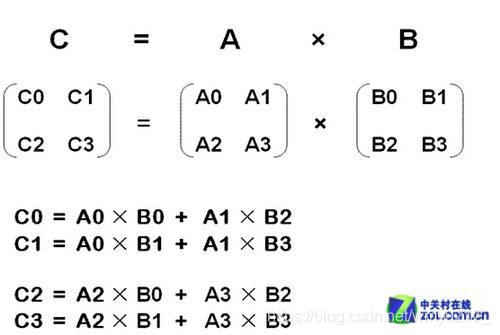
np.dot(x,y) #20*乘:【不推荐使用】
x = np.array([1,1,1])
y = np.array([[1,2,3],[4,5,6]])
print(x * y)结果为:【x将作转换】
[[1 2 3]
[4 5 6]]7.2 关系运算符
**==**:
x = np.array([1,1,1])
y = np.array([1,1,2])
x == y #array([True,True,False]),会进行对应位置比较
x = np.array([1,1,1,4])
x == y #False,维度不一致,直接返回false与:
x = np.array([1,1,1])
y = np.array([1,1,1])
np.logical_and(x,y) #array([ True, True, True])或:np.logical_or(x,y)
非:np.logical_not(x,y)
八、随机模块
8.1 随机函数
np.random.rand() #返回一个数
np.random.random_sample() #返回一个数#所有的值都是从0到1的
np.random.rand(3,2)结果为:
array([[0.46639133, 0.67245453],
[0.36033633, 0.9472259 ],
[0.85873438, 0.37810198]])构造整数:
#返回的是随机的整数,左闭右开
np.random.randint(10,size = (5,4))结果为:
array([[3, 9, 3, 7],
[6, 0, 4, 7],
[1, 5, 3, 5],
[8, 0, 4, 2],
[9, 6, 5, 7]])8.2 案例:高斯分布
mu, sigma = 0,0.1 #均值,方差
np.random.normal(mu,sigma,10)结果为:
array([ 0.06294583, -0.20183854, 0.13620236, -0.07176938, 0.12249114,
-0.09853145, -0.11591499, -0.06742867, -0.12911248, -0.069923 ])改变精度:
np.set_printoptions(precision = 3)再执行上面的语句,结果为:
array([-0.201, -0.142, 0.124, -0.064, -0.173, -0.069, -0.052, -0.145,
0.011, -0.041])8.3 洗牌(打乱顺序)
tang_array = np.arange(10) #array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.random.shuffle(tang_array)
tang_array #array([3, 8, 5, 9, 6, 4, 2, 1, 7, 0])8.4 随机种子
np.random.seed(100) #可取任意值,指定随机种子
mu, sigma = 0,0.1
np.random.normal(mu,sigma,10) #结果将不变随机种子的引入,好处在于当要调节一个参数对结果的影响时,可以保证其他量不变。
九、文件读写
9.1 读文件
写入文件:
%%writefile tang.txt
1 2 3 4 5 6
7 8 9 0 1 10正常情况读文件:
data = []
with open('tang.txt') as f:
for line in f.readlines():
fileds = line.split()
cur_data = [float(x) for x in fileds]
data.append(cur_data)
data = np.array(data)
data #array([[ 1., 2., 3., 4., 5., 6.],[ 7., 8., 9., 0., 1., 10.]])读文件可以使用:
data = np.loadtxt('tang.txt',delimiter = ',') #其中' '为默认分隔符若读入的数据是:
%%writefile tang.txt
x,y,z,w,a,b
1,2,3,4,5,6
7,8,9,0,1,10可以去掉第一行:
data = np.loadtxt('tang.txt',delimiter = ',',skiprows = 1)
data #array([[ 1., 2., 3., 4., 5., 6.],[ 7., 8., 9., 0., 1., 10.]])还可以指定使用的列:usecols = (0,1,4)
9.2 数组保存
tang_array = np.array([[1,2,3],[4,5,6]])
np.savetxt('tang4.txt',tang_array, fmt='%d') #fmt参数指定保存为整数格式
np.savetxt('tang4.txt',tang_array, fmt='%.2f') #保留两个小数位保存结果为:
1 2 3
4 5 6指定逗号为分隔符:
np.savetxt('tang4.txt',tang_array, fmt='%d',delimiter=',')将ndarray结构保存为npy文件:
tang_array = np.array([[1,2,3],[4,5,6]])
np.save('tang_array.npy',tang_array)需要读入时:
tang = np.load('tang_array.npy') #array([[1, 2, 3],[4, 5, 6]])保存为npz文件:
tang_array2 = np.arange(10)
np.savez('tang.npz',a=tang_array,b=tang_array2)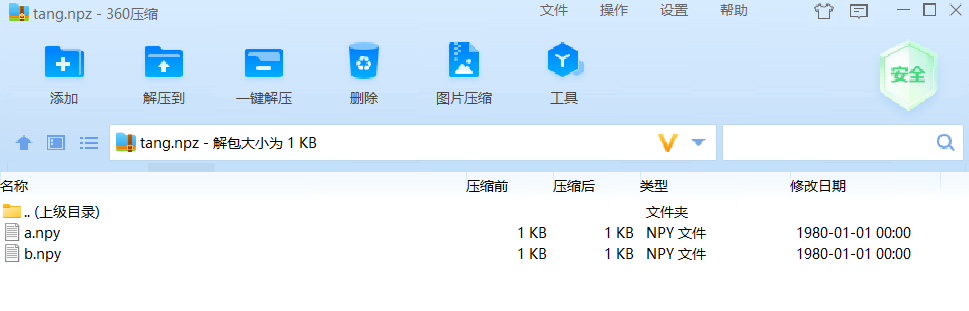
需要读入时:
data = np.load('tang.npz')
data['b'] #array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])十、练习
1.打印当前Numpy版本。
print(np.__version__) #1.21.52.构造一个全零的矩阵,并打印其占用的内存大小。
z = np.zeros((5,5))
print('%d bytes'%(z.size * z.itemsize)) #200 bytes3.打印一个函数的帮助文档,比如numpy.add。
print(help(np.info(np.add)))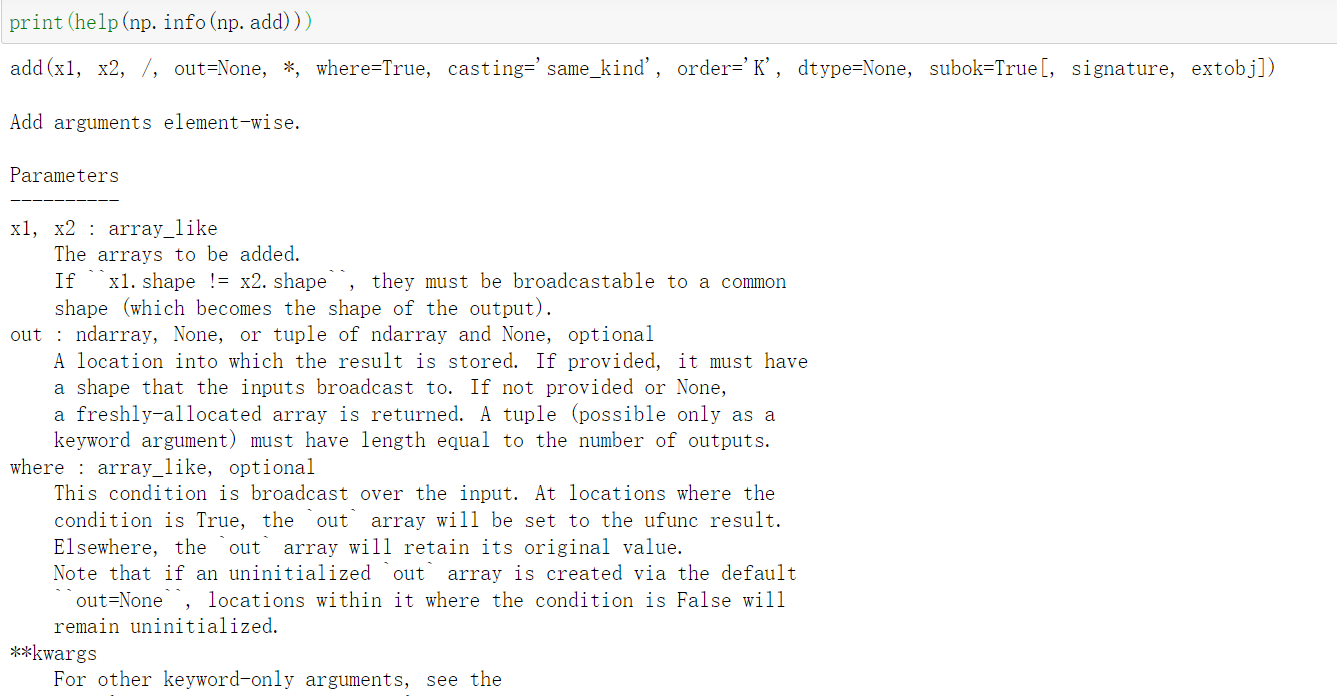
4.创建一个10-49的数组,并将其倒序排列。
tang_array = np.arange(10,50)
tang_array = tang_array[::-1]tang_array的结果为:
array([49, 48, 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33,
32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16,
15, 14, 13, 12, 11, 10])5.找到一个数组中不为0的索引。
np.nonzero([1,2,3,4,5,0,0,0,1234,0,1]) #(array([ 0, 1, 2, 3, 4, 8, 10], dtype=int64),)6.随机构造一个3*3矩阵,并打印其中的最大值与最小值。
tang_array = np.random.rand(3,3)
tang_array.min()
tang_array.max()7.构造一个5*5矩阵,令其值都为1,并在最外层加上一圈0。
tang_array = np.ones((5,5))
tang_array = np.pad(tang_array,pad_width = 1,mode = 'constant',constant_values = 0)tang_array的结果为:
array([[0., 0., 0., 0., 0., 0., 0.],
[0., 1., 1., 1., 1., 1., 0.],
[0., 1., 1., 1., 1., 1., 0.],
[0., 1., 1., 1., 1., 1., 0.],
[0., 1., 1., 1., 1., 1., 0.],
[0., 1., 1., 1., 1., 1., 0.],
[0., 0., 0., 0., 0., 0., 0.]])8.构造一个shape为(6,7,8)的矩阵,并找到第100个元素的索引值。
np.unravel_index(100,(6,7,8))9.对一个5*5的矩阵作归一化操作。
tang_array = np.random.rand(5,6)
tang_min = tang_array.min()
tang_max = tang_array.max()
tang_array = (tang_array - tang_min)/(tang_max - tang_min)tang_array的结果为:
array([[0.762, 0.302, 0.637, 0.539, 0.285, 0.091],
[0.302, 0.452, 0.663, 0.241, 0.644, 0.184],
[0.661, 0.787, 0.789, 0.612, 0.298, 0.703],
[0.872, 0.628, 1. , 0.994, 0.15 , 0. ],
[0.143, 0.939, 0.97 , 0.196, 0.352, 0.549]])10.找到两个数组中相同的值。
z1 = np.random.randint(0,10,10)
z2 = np.random.randint(0,10,10)
print(z1)
print(z2)
print(np.intersect1d(z1,z2))打印结果为:
[3 0 2 5 1 1 0 3 6 7]
[3 6 4 8 6 5 0 0 5 1]
[0 1 3 5 6]11.得到昨天、今天、明天的日期。
yesterday = np.datetime64('today','D') - np.timedelta64(1,'D')
today = np.datetime64('today','D')
tomorrow = np.datetime64('today','D') + np.timedelta64(1,'D') #numpy.datetime64('2022-08-17')12.得到一个月中所有的天。
np.arange('2022-10','2022-11',dtype='datetime64[D]')打印结果为:
array(['2022-10-01', '2022-10-02', '2022-10-03', '2022-10-04',
'2022-10-05', '2022-10-06', '2022-10-07', '2022-10-08',
'2022-10-09', '2022-10-10', '2022-10-11', '2022-10-12',
'2022-10-13', '2022-10-14', '2022-10-15', '2022-10-16',
'2022-10-17', '2022-10-18', '2022-10-19', '2022-10-20',
'2022-10-21', '2022-10-22', '2022-10-23', '2022-10-24',
'2022-10-25', '2022-10-26', '2022-10-27', '2022-10-28',
'2022-10-29', '2022-10-30', '2022-10-31'], dtype='datetime64[D]')13.得到一个数的整数部分。
z = np.random.uniform(0,10,10) #array([1.349,9.791,7.07,8.6,3.872,2.508,2.994,8.569,4.73,6.633])
np.floor(z) #array([1., 9., 7., 8., 3., 2., 2., 8., 4., 6.])14.构造一个数组,让它不能被改变。
z = np.zeros(5)
z.flags.writeable = False
z[0] = 1返回:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [84], in <cell line: 3>()
1 z = np.zeros(5)
2 z.flags.writeable = False
----> 3 z[0] = 1
ValueError: assignment destination is read-only15.打印大数量数的部分值、全部值。
np.set_printoptions(threshold=5) #设置打印规则
z = np.zeros((15,15))打印结果为:
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])指定为np.set_printoptions(threshold=np.inf)。
16.找到在一个数组中,最接近一个数的索引。
z = np.arange(100)
v = np.random.uniform(0,100)
print(v) #80.57286074367852
index = (np.abs(z-v)).argmin()
print(z[index]) #8117.32位float类型和32位int类型转换。
z = np.arange(10,dtype = np.int32)
print(z.dtype) #int32
z = z.astype(np.float32)
print(z.dtype) #float3218.打印数组元素位置坐标与数值。
z = np.arange(9).reshape(3,3)
for index,value in np.ndenumerate(z):
print(index,value)打印结果为:
(0, 0) 0
(0, 1) 1
(0, 2) 2
(1, 0) 3
(1, 1) 4
(1, 2) 5
(2, 0) 6
(2, 1) 7
(2, 2) 819.按照数组的某一列进行排序。
z = np.random.randint(0,10,(3,3))
print(z)
print(z[z[:,1].argsort()])打印结果为:
[[7 7 4]
[1 1 8]
[7 8 8]]
[[1 1 8]
[7 7 4]
[7 8 8]]20.统计数组中每个数值出现的次数。
z = np.array([1,1,1,2,2,3,3,4,5,8])
np.bincount(z) #array([0, 3, 2, ..., 0, 0, 1], dtype=int64)21.如何对一个四维数组的最后两维来求和。
z = np.random.randint(0,10,(4,4,4,4))
res = z.sum(axis=(-2,-1))打印结果为:
array([[73, 70, 56, 72],
[75, 67, 60, 55],
[82, 71, 62, 78],
[68, 61, 83, 72]])22.交换矩阵中的两行。
z = np.arange(25).reshape(5,5)
z[[0,1]] = z[[1,0]] #第一个参数是行,第二个参数是列,这里从略z的打印结果为:
array([[ 5, 6, 7, 8, 9],
[ 0, 1, 2, 3, 4],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])23.找到一个数组中最常出现的数字。
z = np.random.randint(0,10,50)
print(np.bincount(z).argmax()) #324.快速查找TOP K。
z = np.arange(10000)
np.random.shuffle(z)
n = 5
print(z[np.argpartition(-z,n)[:n]]) #[9999 9998 9996 9997 9995]25.去掉一个数组中,所有元素都相同的数据。
np.set_printoptions(threshold = np.inf)
z = np.random.randint(0,3,(10,3))
print(z)
e = np.all(z[:,1:] == z[:,:-1],axis = 1)
print(e)打印结果为:
[[0 0 2]
[2 1 2]
[2 0 2]
[0 2 0]
[0 0 0]
[1 2 1]
[0 0 0]
[1 2 0]
[1 0 1]
[1 0 1]]
[False False False False True False True False False False]
