💡Author:信安2002钱泽枢(ShiQuLiZhi)
🚀欢迎访问我的作业合集:https://sxhthreo.github.io/categories/%E4%BD%9C%E4%B8%9A/
1 前言
数学王子高斯曾在1801年将质因数分解问题和质性检验问题作为数论研究中的两个重大难题着重推介给国际数学界,要求大家竭尽全力想方设法解决这两个问题,因为这两个问题一旦解决,其它很多数学问题都将迎刃而解。如今,质性检验问题(PTP)基本上算是被解决了。三位印度计算机科学家 Agrawal 、Kayal和 Saxena于2002年提出了一种快速的确定性的质性检验算法,简称为AKS质性检验法。但质因数分解问题仍未解决。
在《密码学及应用》课程中,我们曾介绍RSA算法在实际网络场景中的巨大用途。由于对大数的因式分解极其困难,对200位数分解因子需40亿年,RSA算法被认为是一种安全的算法。
在本调研报告中,我将阐述在因式分解的可能解决方案,并分析其可行性。
最有效的因式分解算法主要可分为两大类:
- 运行时间主要依赖于待分解整数
N的大小,并不十分依赖于找到的因子p的大小,如连分数法、数域筛法 - 运行时间主要依赖于找到的
N的因子p的大小,如试除法、Pollard’s Rho算法、Pollard’s P-1算法、椭圆曲线算法等
2 试除法与费马分解法
试除法是最简单而最直接的方法,即用直到sqrt(n)的每一个素数去除n。该方法在$n<10^{20}$基本可行,且如果n有小的因子会比较有效。我们可以得到以下的利用试除法分解质因数($n = p_{1}^{\alpha_{1}}…p_{k}^{\alpha_{k}}$)算法:
void divide(int x)
{
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0) //若此条件成立,i一定是质数
{
int s = 0; //s为次数
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl; //单独处理,唯一一个大于sqrt(n)的质因子
cout << endl;
}我们可以看到:由于 $n$ 不包含任何从 $2$ 到 $i-1$ 之间的质因子(已经被除干净了),若x % i = 0成立,i不包含其中的所有质因子,故i一定是质数,且n中最多只包含一个大于sqrt(n)的质因子。当n = 2^k时,时间复杂度为O(log n),而最坏时间复杂度为O(sqrt(n)),平均情况是介于两者之间。
若两个因子相差不大,我们可以采用费马分解法求解两个因子p和q。构造平方差:
$n=p*q=\frac{1}{4}(p+q)^{2}-\frac{1}{4}(p-q)^{2}$
由于p和q相差不大,则p-q相对于n和$(p+q)^{2}$来说可以忽略不计,则有$2\sqrt {n}\approx p+q$。也就是说,通过不断尝试,即可将p和q计算出来。Python代码如下:
def fermat(n, verbose=True):
a = isqrt(n) # int(ceil(n**0.5))
b2 = a*a - n
b = isqrt(n) # int(b2**0.5)
count = 0
while b*b != b2 and count<1000000:
a = a + 1
b2 = a*a - n
b = isqrt(b2) # int(b2**0.5)
count += 1
p=a+b
q=a-b
return p, q3 通用整数因式分解方法
是指用此方法分解任何给定大小的整数所用时间与分解任何同样大小的整数所用时间相同。这种方法的理论依据是:
若有两个整数x和y满足:$x^2\equiv y^2(\mod N),0<x<y<N,x\neq y,x+y\neq N$(1),因为N|(x+y)(x-y),N不是(x+y),(x-y)的因子,则gcd(x-y,N)和gcd(x+y,N)可能为N的非平凡因子。(1)式常称为勒让德同余。
用勒让德同余来分解因子只需执行以下两步:
- 找同余式$x^2\equiv y^2(\mod N)$的一个非平凡解
- 用欧几里得算法计算
N的因子:(d,d')=(gcd(x-y,N),gcd(x+y,N))
3.1 连分数法
若W很小,且$x^{2}\equiv W(\mod N)$,则对某个k和d,有$x^{2}\equiv W+kNd^2$,因而$(\frac{x}{d})^2-kN=\frac {W}{d^2}$也会很小。换句话说,有理数$\frac{x}{d}$逼近$\sqrt {KN}$。而实数的连分数展开式可以给出该实数很好的有理数逼近。
连分数:
连分数(continued fraction)是特殊繁分数。如果a0,a1,a2,…an,…都是整数,则将分别称为无限连分数和有限连分数。可简记为a0,a1,a2,…,an,…和a0,a1,a2,…,an。一般一个有限连分数表示一个有理数,一个无限连分数表示一个无理数。如果a0,a1,a2,…,an,…都是实数,可将上述形式连分数分别叫无限连分数和有限连分数。

3.2 二次筛法
二次筛法的算法流程如下:
(1)选定一组因子基:$p_{1},p_{2},…,p_{m}$
(2)通过在因子基上分解诸整数$Q(x)=x^2-N,x=\lfloor \sqrt N\rfloor +1,\lfloor \sqrt N\rfloor +2,…$来寻找s和t使得$s^2\equiv t^2(\mod N),s\neq t(\mod N)$,从而分解N
因子基的选择应满足:当p是奇素数时,存在整数x使$p|Q(x)$。若不存在,则不选其为因子基。
以N=4033为例讲解二次筛法的算法执行步骤:
(1)选择因子基$FB={2,3,7,13,17,19}$(5和11不能除尽$Q(x)$中的任何数,故不选)
(2)通过对从x=64到73的$Q(x)$除因子基中的素数来进行筛选。如果剩余下的数相当小,则它已经分解成功。完整的分解记在left列中:
$\begin{array}{lccccccccc}
x & Q(x)=x^{2}-N & 2 & 3 & 7 & 13 & 17 & 19 & \text { 剩余的数 } & \text { left } \
64 & 63 & - & 21 & 3 & - & - & - & 3 & 3^{2} \times 7 \
65 & 192 & 96 & 32 & - & - & - & - & 32 & 2^{6} \times 3 \
66 & 323 & - & - & - & - & 19 & 1 & 1 & 17 \times 19 \
67 & 456 & 228 & 76 & - & - & - & 4 & 4 & 2^{3} \times 3 \times 19 \
68 & 591 & - & 197 & - & - & - & - & 197 & - \
69 & 728 & 364 & - & 52 & 4 & - & - & 4 & 2^{3} \times 7 \times 13 \
70 & 867 & - & 289 & - & - & 17 & - & 17 & 3 \times 17^{2} \
71 & 1008 & 504 & 168 & 24 & - & - & - & 24 & 2^{4} \times 32 \times 7 \
72 & 1151 & - & - & - & - & - & - & 1151 & -
\end{array}$
(3)对所有这样的分解,其方次的奇偶性记在0/1矩阵中:
$\begin{array}{ccccccc}
Q(x) & 2 & 3 & 7 & 13 & 17 & 19 \
64 & 0 & 0 & 1 & 0 & 0 & 0 \
65 & 0 & 1 & 0 & 0 & 0 & 0 \
66 & 0 & 0 & 0 & 0 & 1 & 1 \
67 & 1 & 1 & 0 & 0 & 0 & 1 \
69 & 1 & 0 & 1 & 1 & 0 & 0 \
70 & 0 & 1 & 0 & 0 & 0 & 0 \
71 & 0 & 0 & 1 & 0 & 0 & 0
\end{array}$
(4)寻找使它们所含的方次都是偶数的相应行,即可得到所求s和t,如上述矩阵的65和70、64和71所在行都满足行和为0,则有:
$\begin{array}{l}
(65 \times 70)^{2}-\left(2^{3} \times 3 \times 17\right)^{2}=(4550+408)(4550-408)=4958 \times 4142 \
(64 \times 71)^{2}-\left(2^{3} \times 3^{2} \times 7\right)^{2}=(4544+252)(4544-252)=4796 \times 4292
\end{array}$
两者都可导出4033的分解:
4958和4292与4033共有因子37,而4142和4796与4033共有因子109(最大公因数在大数范围内是可以在给定时间内得到的),则:$4033=37\times 109$
筛法不仅可以对表达式$x^2-N$进行,也可以处理更一般的形如$(ax+b)^2-N$的二次多项式。改进算法称为多重多项式二次筛法(MPQS)。
在合理的假设下,用$QS/MPQS$方法分解整数N的时间复杂度为:$O(\exp ((1+o(1)) \sqrt{\log N \log \log N}))=O\left(N^{(1+o(1)) \log \log N / \log N}\right)$
4 专门用途的因式分解方法
“专门”是指因子分解方法的成功依赖于待分解数的一些特殊性质。一般指待分解数的因子都很小;或要求带分解数或它的因子有特殊的数学形式。专门的方法并不总能成功,但在使用CFRAC、MPQS或NFS这些通用方法之前尝试一下它们是有帮助的。
4.1 Pollard’s Rho算法
引理:生日悖论:
我们来考虑这样一种情况:在$[1,1000]$里面取一个数,取到我们想要的数(比如说,42),成功的概率是多少呢?显然是$\frac{1}{1000}$.
若随意在$[1,1000]$里面取两个数,我们取两个数的差值绝对值。也就是说,在$[1,1000]$里面任意选取两个数$i , j$,问$|i-j|=42$的概率是多大?答案会扩大到$\frac{1}{500}$左右,也就是将近扩大一倍。我们可以用下列的方式直观理解:$i$在$[1,1000]$里面取出一个正整数的概率是$100%$,而取出$j$满足$|i-j|=42$的概率差不多就是原来的一倍:$j$取$i-42$和$i+42$都是可以的.
这给了我们一点启发:这种”组合随机采样“的方法是不是可以大大提高准确率呢?
这个便是生日悖论的模型了。假如说一个班上有k个人,如果找到一个人的生日是4月2日,这个概率的确会相当低.但是如果单纯想找到两个生日相同的人,这个概率是不是会高一点呢? 可以暴力证明:如果是k个人生日互不相同,则概率为:$p=\frac{365}{365}\cdot\frac{364}{365}\cdot\frac{363}{365}\cdot\dots\cdot\frac{365-k+1}{365}$ ,故生日有重复的现象的概率是:$\text{P}(k)=1-\prod\limits_{i=1}^{k}{\frac{365-i+1}{365}}$。我们随便取一个概率:当$P(k) \geqslant \frac{1}{2}$时,解得$k \gtrsim 23$.这意味着一个有 23 个人组成的班级中,两个人在同一天生日的概率至少有$50%$!当k取到 60 时,$\text{P}(k) \approx 0.9999$。这个数学模型和我们日常的经验严重不符,这也是”生日悖论”这个名字的由来。
该算法的流程如下:
给定整数n,设初始值$x=2,y=x^{2}+1$。
(1)计算$g=gcd(x-y,n)$;
(2)若$1<g<n$,则停止,g为n的一个因子;
(3)若$g=1,x^{2}+1 \rightarrow x,(y^{2}+1)^{2}+1% n\rightarrow y$,返回(1)
(4)若$g=n$,失败,需要对算法重新进行初始化。有一种方法是,考虑生成一个伪随机序列,用组合的方式生成因数来计算gcd,函数为$y=x^{2}+c(mod N)$,其中c是我们用rand生成的一个函数,函数的大致图像如图:
可以看出,虽然它生成的数较为随机,但还是存在循环节,所以才叫伪随机数,生成数列的轨迹很像希腊字母$\rho$,所以这个算法也叫pollard_rho算法。
有一种基于floyd算法优化的pollard_rho算法:由于pollard的数列存在循环节,为了判环,我们类比floyd算法,用龟兔赛跑的思想,假设兔子速度是乌龟速度的一倍,过了时间i后,$t=i,r=2i$,此时两者得到的数列值$x_t=x_i,x_r=x_{2i}$。若相遇,则路径长是环长的整数倍,我们将跳出查找,重新调整参数c。伪代码表示如下:
int pollard_rho(int N)
{
int c=rand()%(N-1)+1;
int t=f(0,c,N),r=f(f(0,c,N),c,N); //两倍速跑
while(t!=r)
{
int d=gcd(abs(t-r),N);
if(d>1)
return d;
t=f(t,c,N),r=f(f(r,c,N),c,N);
}
return N; //没有找到,重新调整参数c
}经过理论推导可以得到该算法的时间复杂度为$O(n^{1/4})$。
4.2 Pollard’s P-1算法
选择随机整数b,1 < b < n:
(1)计算g=gcd(b,n),若g>1,找到真因子,停止;否则,令$p_{i}={2,3,5,7,…}$
(2)令i=0,$q=p_{i},r=\lfloor log_{q} n\rfloor,b=b^{q^r}\mod n$,计算$g=gcd(b-1,n)$:
g=1:i++,继续g=n:失败,结束1 < g < n:g为因子,结束
**[例]**计算9991的因式分解。
(1)取初值b = 3,计算g = gcd(3,9991) = 1;
(2)$q = 2,r = floor(log_{2}^{9991})=13$
$b^{q^{r}}\mod n=3^{2^{13}}\mod 9991=229$
$g=gcd(229-1,9991)=1$,则取$q=3$,继续;
(3)$q=3,r=floor(log_{3}9991)=8$
$b^{q^{r}}\mod n=3^{3^{8}}\mod 9991=3202$
$g=gcd(3202-1,9991)=97$,则$n=9991$的其中一个因子97。
故$9991=97*103$。
有定义:如果一个整数的所有素因子都不大于B,则称这个整数是B-Smooth数。如:12=2*2*3,则12是3-Smooth数。
若$p_{1},p_{2},…,p_{n}$是随机在小于B的范围内选取,则能成功分解的概率较大。
#include<iostream>
#include<algorithm>
using namespace std;
long long qmi(int a,int t,long long val)
{
long long ans = 1;;
while (t) {
if (t & 1) {
ans = ans *a;
ans %= val;
}
t >>= 1;
a *= a;
a %= val;
}
return ans;
}
long long gcd(long long a, long long b)
{
if (b) {
return gcd(b, a % b);
}
else {
return a;
}
}
long long pollardp_1(long long val,int pmax)
{
long long B = 1;
for (int i = 2; i <= pmax; i++) {
B *= i;
}
long long y = qmi(2, B, val) - 1;
long long ans = gcd(max(y,val),min(y,val));
if (ans > 1 && ans < val)return ans;
return -1;
}
int main()
{
long long val = 767;
printf("%ld", pollardp_1(val,4));
}4.3 椭圆曲线算法
Lenstra于1987年设计的椭圆曲线算法(ECM)实际上是Pollard p-1算法的一般化,该算法牵涉到定义在模p椭圆曲线上的群,成功率依赖于接近p的一个整数只有小的素因子。
算法执行过程如下:
随机选取阶为g的群G,g接近于p,则可在群G上而不是群$Z_p$上执行与Pollard p-1算法类似的计算。
若g的所有素因子均小于界B,则可找到N的一个素因子;否则选取不同的群G(通常是不同的阶g),重复上述步骤直到找到因子为止。
5 数域筛法



6 谈谈RSA算法
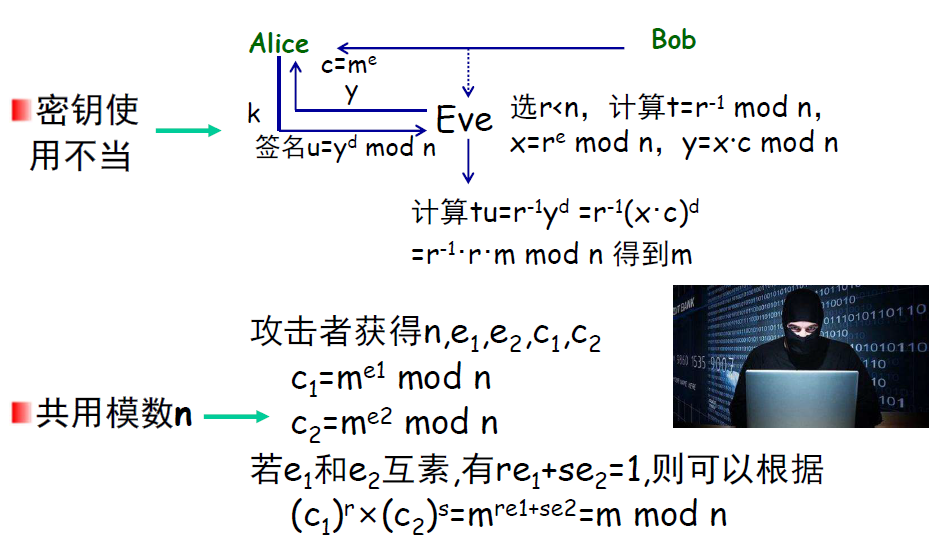
RSA算法的过程如下:

虽然大数的因式分解在目前仍是一个难题,但针对RSA算法,也有一些人为因素使得攻击者得到明文,如密钥使用不当,共用模数等,这些是在使用该算法时需要避免的问题:
7 结语
大数的因式分解是密码学领域的三大难题之一(还有两大是离散对数问题与椭圆曲线离散对数问题),目前还没有通用方法能够解出大于给定位数的任意数的因式分解。本文阐述的因式分解方法各有各的优点,其中第四模块的因式分解方法主要用于满足给定特征的数字的因式分解,虽然这类方法可能有条件限制,但可以分解更大位数的数字,而第三模块的因式分解方法普适性更强,但时间复杂度也更高,在数字位数过大时可能需要执行很长时间。
本次调研,既丰富了我的知识面,又对密码学课程中学过的一些数论知识有所巩固,收获很大。

