💡Author:信安2002钱泽枢(ShiQuLiZhi)
🚀欢迎访问我的作业合集:https://sxhthreo.github.io/categories/%E4%BD%9C%E4%B8%9A/
一、调研学习相似度的定义与应用
调研学习相似度的定义方法与应用场景。
1.1 相关(相似)系数
皮尔森(Pearson)相关系数、斯皮尔曼(Spearman)相关系数和肯德尔(Kendall)相关系数并称为统计学三大相关系数。
1.1.1 皮尔逊相关系数(Pearson Correlation Coefficient)
在统计学中,皮尔逊相关系数(Pearson Correlation Coefficient),又称皮尔逊积矩相关系数(Pearson Product-Moment Correlation Coefficient,简称 PPMCC 或 PCCs),是用于度量两个变量X和Y之间的相关(线性相关),其值介于 $-1$ 与 $1$ 之间,公式是:
$\rho_{x y}=\frac{\operatorname{Cov}(x, y)}{\sqrt{D(x)} \sqrt{D(y)}}=\frac{E[(x-E x)(y-E y)]}{\sqrt{D(x)} \sqrt{D(y)}}$
推导过程如下,其中$Z$代表在正态分布中,数据偏离中心点的距离,计算过程是变量减掉平均数再除以标准差:
$\begin{array}{l}
r_{x y}=\frac{\sum Z x Z y}{N} \
=\frac{\sum\left(\frac{X-\bar{X}}{S x}\right)\left(\frac{Y-\bar{Y}}{S y}\right)}{N} \
=\frac{\sum(X-\bar{X})(Y-\bar{Y})}{N \bullet S x S y} \
=\frac{\sum(X-\bar{X})(Y-\bar{Y})}{N \bullet\left(\sqrt{\left.\frac{1}{n} \sum_{i=1}^{n}\left(X_{i}-\bar{X}\right)^{2}\right)\left(\sqrt{\frac{1}{n} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}}\right)}\right.} \
=\frac{\sum(X-\bar{X})(Y-\bar{Y})}{\left(\sqrt{\sum_{i=1}^{n}\left(X_{i}-\bar{X}\right)^{2}}\right)\left(\sqrt{\sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}}\right)}
\end{array}$
皮尔逊相关的约束条件:
- 两个变量间有线性关系
- 变量是连续变量
- 变量均符合正态分布,且二元分布也符合正态分布
- 两变量独立
相关系数的取值范围是$[-1,1]$。相关系数定量地刻画了 $x$ 与 $y$ 的相关程度,即 $ρ_{xy}$ 越大,相关程度越大; $ρ_{xy}$ 越小,对应相关程度越低。当 $x$ 与 $y$ 线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关);当$ρ_{xy}=0$时,对应的相关性最低。
类似地,有相关距离的定义:$d_{xy}=1−ρ_{xy}$.
1.1.2 斯皮尔曼相关系数(Spearman Correlation Coefficient)
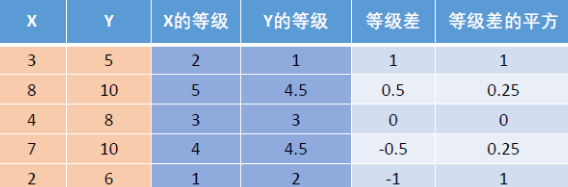
$X$ 和 $Y$ 为两组数据,其斯皮尔曼(等级)相关系数为:
$r_{s}=1-\frac{6 \sum_{i=1}^{n} d_{i}^{2}}{n\left(n^{2}-1\right)}$
其中,$d_i$为$X_i$和$Y_i$之间的等级差。可以证明:$r_s$位于 $-1$ 和 $1$ 之间。
等级差代表一个数的等级,即将它所在的一列按照从小到大排序后,这个数所在的位置;若有的数数值相同,则取它们所在位置的算术平均。
1.1.3 肯德尔相关系数(Kendall Correlation Coefficient)
$n$ 个同类的统计对象按特定属性排序,其他属性通常是乱序的。同序对(concordant pairs)和异序对(discordant pairs)之差与总对数$\frac{n*(n-1)}{2}$的比值定义为肯德尔相关系数,也称Kendall秩相关系数。
$\tau=\frac{\text { (number of concordant pairs) }-\text { (number of discordant pairs) }}{\frac{1}{2} n(n-1)}$
肯德尔相关系数有以下特性:
如果两个属性排名是相同的,系数为1 ,两个属性正相关;
如果两个属性排名完全相反,系数为-1 ,两个属性负相关;
如果排名是完全独立的,系数为0。
1.1.4 杰卡德相似系数(Jaccard Index)
两个集合 $A$ 和 $B$ 的交集元素在 $A$,$B$ 的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号 $J(A,B)$ 表示。它是衡量两个集合相似度的一种指标,公式为:
$J(A, B)=\frac{|A \cap B|}{|A \cup B|}$
杰卡德相似度算法没有考虑向量中潜在数值的大小,而是简单的处理为0和1。但经过处理之后,杰卡德方法的计算效率是比较高的。
类似地,杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
$J_{\delta}(A, B)=1-\frac{|A \cap B|}{|A \cup B|}=\frac{|A \cup B|-|A \cap B|}{|A \cup B|}$
1.2 样本间的距离
在机器学习中,无论是分类问题、聚类问题或降维问题,经常需要度量不同样本之间的相似性,常用方法则是计算样本间的距离。
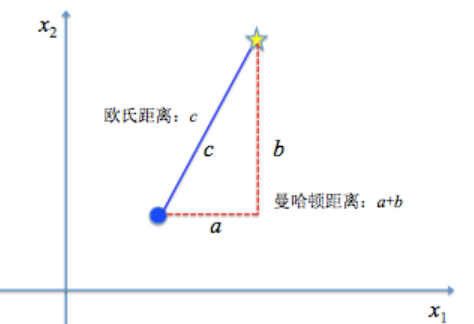
1.2.1 欧氏距离(Euclidean Distance)
欧氏距离是一个通常采用的距离定义,指在$n$维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。
两个$n$维向量$\mathbf{x}{1}=(x{11},x_{12},…,x_{1n})$与$\mathbf{x}{2}=(x{21},x_{22},…,x_{2n})$间的欧氏距离为:
$d\left(\mathbf{x}{1}, \mathbf{x}{2}\right)=\sqrt{\sum_{i=1}^{n}\left(x_{1 i}-x_{2 i}\right)^{2}}$
1.2.2 曼哈顿距离(Manhattan Distance)
曼哈顿距离是由十九世纪的赫尔曼·闵可夫斯基所创的词汇,是一种使用在几何度量空间的几何学用语,用以标明两个点在标准坐标系上的绝对轴距总和。
两个$n$维向量$\mathbf{x}{1}=(x{11},x_{12},…,x_{1n})$与$\mathbf{x}{2}=(x{21},x_{22},…,x_{2n})$间的曼哈顿距离为:
$d\left(\mathbf{x}{1}, \mathbf{x}{2}\right)=\sum_{i=1}^{n}\left|x_{1 i}-x_{2 i}\right|$
示意图如图所示:
1.2.3 切比雪夫距离(Chebyshev Distance)
二个点之间的切比雪夫距离定义是其各坐标数值差绝对值的最大值。
两个$n$维向量$\mathbf{x}{1}=(x{11},x_{12},…,x_{1n})$与$\mathbf{x}{2}=(x{21},x_{22},…,x_{2n})$间的切比雪夫距离为:
$d\left(\mathbf{x}{1}, \mathbf{x}{2}\right)=\max {i}\left(\left|x{1 i}-x_{2 i}\right|\right)$
也等价于$d\left(\mathbf{x}{1}, \mathbf{x}{2}\right)=\lim {k \rightarrow \infty}\left(\sum{i=1}^{n}\left(x_{1 i}-x_{2 i}\right)^{k}\right)^{1 / k}$
1.2.4 闵氏距离(Minkowski Distance)
闵氏距离是以俄裔德国数学家闵可夫斯基命名的,它代表的不是一种距离,而是一组距离的定义。
两个$n$维向量$\mathbf{x}{1}=(x{11},x_{12},…,x_{1n})$与$\mathbf{x}{2}=(x{21},x_{22},…,x_{2n})$间的闵氏距离为:
$d\left(\mathbf{x}{1}, \mathbf{x}{2}\right)=\sqrt[k]{\sum_{i=1}^{n}\left(x_{1 i}-x_{2 i}\right)^{k}}$
其中 $k$ 是一个变参数。当$k=1$时,就是曼哈顿距离;当$k=2$时,就是欧氏距离;当$k→∞$时,就是切比雪夫距离。根据变参数的不同,闵氏距离可以表示一类的距离。
1.2.5 马氏距离(Mahalanobis Distance)
马氏距离是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。
两个$n$维向量$\mathbf{x}{1}=(x{11},x_{12},…,x_{1n})$与$\mathbf{x}{2}=(x{21},x_{22},…,x_{2n})$间的马氏距离为:
$d\left(\mathbf{x}{1}, \mathbf{x}{2}\right)=\sqrt{\left(\mathbf{x}{1}-\mathbf{x}{2}\right) \mathbf{S}^{-1}\left(\mathbf{x}{1}-\mathbf{x}{2}\right)^{T}}$
其中$S$为 $\mathbf{x}{1},\mathbf{x}{2}$ 的协方差矩阵。如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离。
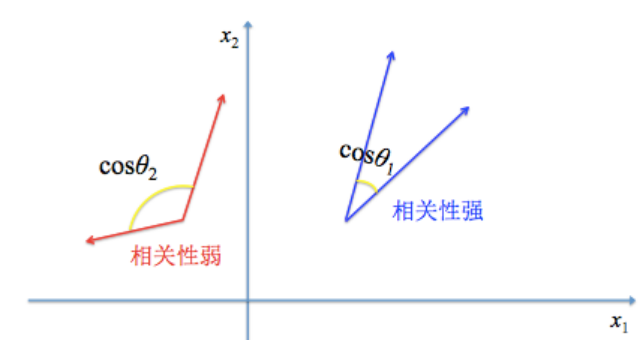
1.2.6 夹角余弦距离(Cosine Dsitance)
夹角余弦距离也称余弦相似度。
两个$n$维向量$\mathbf{x}{1}=(x{11},x_{12},…,x_{1n})$与$\mathbf{x}{2}=(x{21},x_{22},…,x_{2n})$间的夹角余弦距离为:
$\cos \theta=d\left(\mathbf{x}{1}, \mathbf{x}{2}\right)=\frac{\mathbf{x}{1} \mathbf{x}{2}^{T}}{\left||\mathbf{x}{1}\right||\left||\mathbf{x}{2}\right||}=\frac{\sum_{i=1}^{n} x_{1 i} x_{2 i}}{\sqrt{\sum_{i=1}^{n} x_{1 i}^{2}} \sqrt{\sum_{i=1}^{n} x_{1 i}^{2}}}$
根据余弦函数的性质可知夹角余弦取值范围为$[−1,1]$。相似性强弱随着夹角余弦值单调递增:夹角余弦越大表示两个向量的夹角越小,两者的相似性较强;夹角余弦越小表示两向量的夹角越大,两者的相似性较弱。当两个向量的方向重合时,夹角余弦取最大值$1$,当两个向量的方向完全相反时,夹角余弦取最小值$-1$。
1.2.7 汉明距离
汉明距离是以理查德·卫斯里·汉明的名字命名的。两个等长字符串 $s_1$ 与 $s_2$ 之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。若想快速计算两个字符串的汉明距离,可以对两个字符串进行异或运算,然后统计结果为1的个数,那么这个数就是两者的汉明距离。例如字符串“1111”与“1001”之间的汉明距离为2,“11110011”与“10011000”之间的汉明距离为5。
汉明距离在计算机网络中被应用于数据传输差错控制编码的距离度量方式。
1.3 相似度的应用
1.3.1 KNN算法
$k-$近邻算法(k-Nearest Neighbour algorithm),又称为 $KNN$ 算法。
$KNN$ 算法的工作原理是:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻近的 $k$ 个实例,如果这 $k$ 个实例的多数属于某个类别,那么新数据就属于这个类别。可以简单理解为:由那些离 $X$ 最近的 $k$ 个点来投票决定X归为哪一类。
$KNN$ 算法的三个基本要素是:$k$ 值的选择、距离度量和分类决策规则。当训练集、距离度量、k值及分类决策规则确定后,对于任何一个新的输入实例,它所属的类唯一地确定。
$KNN$ 算法的基本步骤是:
- 计算已知类别数据集中的点与当前点之间的距离,距离的计算方法可以在上一节中所描述的样本间距离的计算方法中进行选取;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测类别。
一般而言,从 $k = 1$ 开始,随着的逐渐增大,$k-$近邻算法的分类效果会逐渐提升;在增大到某个值后,随着的进一步增大,$k-$近邻算法的分类效果会逐渐下降。我们往往需要通过**交叉验证(Cross Validation)**等方法评估模型在不同取值下的性能,进而确定具体问题的K值。
1.3.2 文本相似度测算
文本相似度主要用于各种搜索引擎的类似文章的推荐,或者购物网站的类似商品推荐,点评网站/微博微信平台上的类似内容推荐。
如果两个文档/两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
目前主要有以下几大类方法:
==基于关键词匹配==:
我们可以采用N-gram 相似度:
基于N-Gram模型定义的句子(字符串)相似度是一种模糊匹配方式,通过两个长得很像的句子间的“差异”来衡量相似度。
N-Gram相似度的计算是指按长度N切分原句得到词段,也就是原句中所有长度为N的子字符串。对于两个句子$S$和$T$,则可以从共有子串的数量上去定义两个句子的相似度。
$\text { Similarity }=\left|G_{N}(S)\right|+\left|G_{N}(T)\right|-2 *\left|G_{N}(S) \cap G_{N}(T)\right|$
其中, $G_{N}(S)$ 和 $G_{N}(T)$分别表示字符串 $S$ 和 $T$ 中 N-Gram 的集合,$N$ 一般取2或3。字符串距离越近,它们就越相似,当两个字符串完全相等时,距离为0。
还可以采用1.1.4节介绍的Jaccard 相似度:
Jaccard相似度的计算相对简单,原理也容易理解。就是计算两个句子之间词集合的交集和并集的比值。该值越大,表示两个句子越相似,在涉及大规模并行运算的时候,该方法在效率上有一定的优势。
其公式为:$J(A, B)=\frac{|A \cap B|}{|A \cup B|}$,其中$0≤J(A,B)≤1$
==基于向量空间==:
关于如何表达词意目前有三种方法,第一种的代表就是 WordNet,它提供了一种词的分类资源但是缺少了词之间的细微区别,同时它也很难计算词之间的相似度;第二种就是 Discrete representation,如One-hot representation,它的向量维度和词典的长度相同,因此向量维度可能十分高,同时由于向量之间本身正交,无法计算词之间的相似度;第三种就是 Distributed representation,基本想法就是将每个词映射为一个固定长度的短向量(相对于one-hot representation而言),所有这些词构成一个词向量空间,每一个向量视为空间中的一个点,在这个空间引入“距离”,就可以根据词之间的距离来判断它们之间的相似性,代表方法如word2vec, LDA等。
目前采用的其中一种改进方法是:
- 语料分词
- 语料向量化
- 将语料转换为基于关键词的词频向量
- 为了避免文章长度的差异,长度悬殊时可以考虑使用相对词频使用
TF-IDF算法,找出两篇文章的关键词。例如取前20个,或者前50个计算相似度 - 计算两个向量的余弦相似度,值越大就表示越相似
TF-IDF的核心思想是:在一篇文章中,某个词语的重要性与该词语在这篇文章中出现的次数成正相关,同时与整个语料库中出现该词语的文章数成负相关。其中有两个概念:
TF(term frequency):词频,某一个给定的词语在该文件中出现的频率,表示一个词语与该文章的相关性。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。IDF(inverse document frequency):逆向文件词频,表示一个词语出现的普遍程度。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到。
一篇文章中某个词语的重要程度,可以标记为词频和逆向文件词频的乘积,即:$tfidf=tf∗idf$
通过计算出文档中每个词的TF-IDF值,然后结合相似度计算方法(一般采用余弦相似度)就可以计算两个文档的相似度。采用TF-IDF的前提是“文章的词语重要性与词语在文章中出现的位置不相关”。
==基于深度学习==:
随着深度学习在图像和语音识别中取得不错的进展,近些年深度学习也开始应用于自然语言处理的不同应用中,语义相似性匹配问题已经逐渐从人工设计特征转向分布式表达和神经网络结构相结合的方式。
DSSM是一种深度学习语义匹配模型,在检索场景下,利用用户的点击数据来训练语义层次的匹配。
DSSM利用点击率来代替相关性,点击数据中包含大量的用户问句和对应的点击文档,这些点击数据将用户的问题和匹配的文档连接起来。
下图就是利用DNN的DSSM结构。DNN的输入是用户问句和对应文档的高维未归一化向量(如图中的500K维),DNN的输出是一个低维的语义特征空间向量(如图中的128维)。
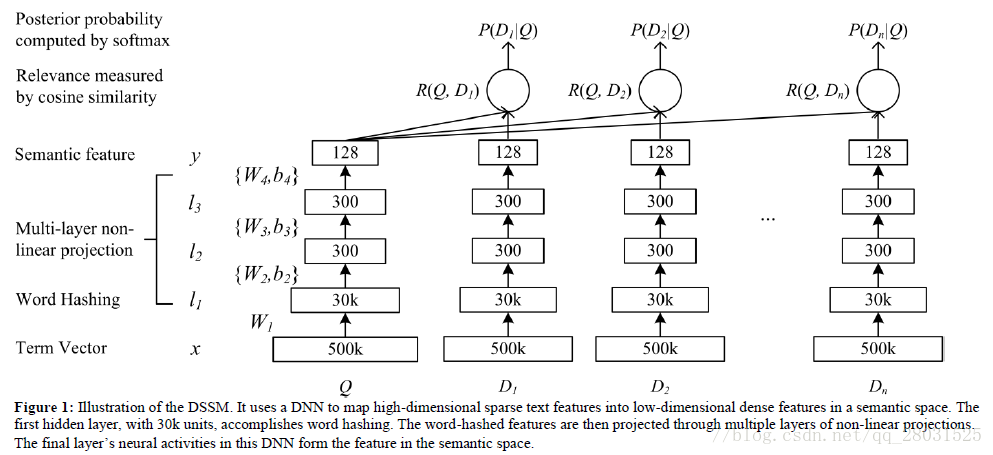
上图中的Multilayer non-linear projection采用了非线性的多层神经网络,利用tanh作为激活函数,同时问句和文档的神经网络共享参数,并在DNN的输出层利用cosine similarity计算问句和文档之间的语义相关性。有以下公式:
$R(D, Q)=\operatorname{cosine}\left(y_{Q}, y_{D}\right)=\frac{y_{Q}^{T} y_{D}}{\left|y_{Q}\right|\left|y_{D}\right|}$
其中 $y_Q$ 和 $y_D$ 表示DNN输出层问句和文档的低维语义向量,然后通过softmax得到条件概率分布。
1.4 总结与讨论
对于不同的应用场景,可以采用不同的衡量相关系数和样本间的距离的方法来测算数据间的相似度,并结合图论、机器学习、深度学习等实际问题分别进行选择。通过这次调研,我了解并掌握了不同的相似度测算方法,其中有些方法是高等数学、概率论、机器学习课程有所提到的,我将在今后对它们加以应用。
二、确定上班路线
W先生每天驾车去公司上班。W先生的住所位于A,公司位于F,图中的直线段代表公路,交叉点代表路口,直线段上的数字代表两路口之间的平均行驶时间。现在W先生的问题是要确定一条最省时的上班路线。

2.1 迪杰斯特拉算法
2.1.1 算法思路
我们可以通过迪杰斯特拉算法求最短路径的方法确定上班路线。迪杰斯特拉算法的一般步骤是:
算法求单个源点到其余各顶点的最短路径,计算思路是离源点最低路径长度的开序,运用到的思想是贪心(每次取离源点最近的点)。设C数组为蓝点集,起点为红点。当红点集合加入值时,关联的蓝点将更新最短路径。
我们通过在更新最短路径时对路径经过的点进行记录,可以得到最后的上班路线。
2.1.2 算法图解
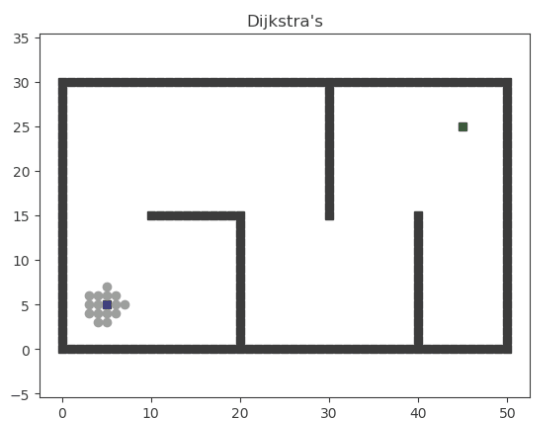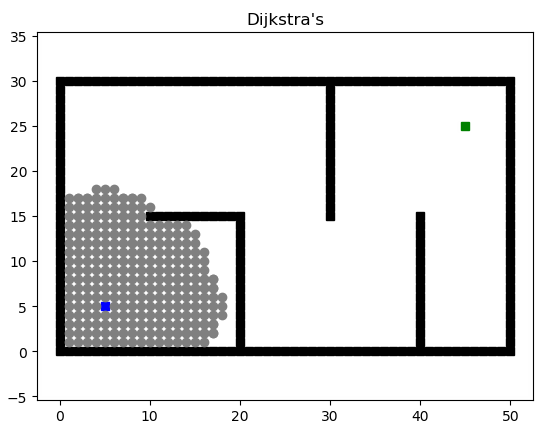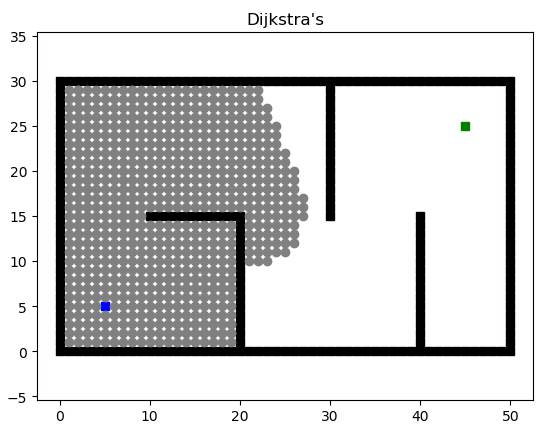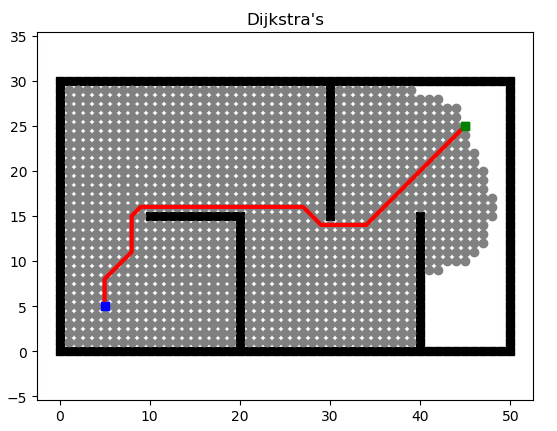
markdown文档中这是一个动图……本算法直接套用迪杰斯特拉算法即可,不多赘述。
2.1.3 代码设计
struct graph
{
int n, m;
int g[N][N];
};
void dijkstra(struct graph &graph)
{
bool st[N] = { 0 };
int path[N] = { 0 }, res[N] = { 0 }, dist[N] = { 0 };
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; //初始化
for (int i = 0; i < graph.n; i++)
{
int t = -1; //t为-1表示还未选择一个点
for (int j = 1; j <= graph.n; j++)
{
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j; //选取还未被选择的且距离最近的点
}
st[t] = true;
for (int j = 1; j <= graph.n; j++)
{
if (dist[j] > dist[t] + graph.g[t][j])
{
dist[j] = min(dist[j], dist[t] + graph.g[t][j]);
path[j] = t;
}
}
}
cout << "需要的时间最短为:" << dist[graph.n] << endl << "路径依次是:";
int j = graph.n, i = 0;
res[i] = graph.n; // 记录终点
while (path[j] != 0) // 将路径存放到结果数组中
{
res[++i] = path[j];
j = path[j];
}
for (int m = i; m >= 0; m--) // 逆序输出
{
cout << res[m] << " ";
}
}2.1.4 算法复杂度分析
Dijkstra算法的时间复杂度为:
对于邻接矩阵表示,为$O\left( n^{2} \right)$(其中$n=\left| V \right|$);
对于邻接表表示,为$O\left( n+|E|\right)$(其中$n=\left| V \right|$,$|E|$为边数[结点的度的加和])。
在这里,我采用的是邻接矩阵进行表示,故算法时间复杂度为$O\left( n^{2} \right)$。
2.2 动态规划算法
2.2.1 算法思路
仔细观察此图,发现每个数都是由其左边/下面的数的最短路径和其左边/下面的数到该数的距离的加和得到。我们可以采用动态规划思想,从上到下、从左到右遍历各点,当遍历到最后一个点时,即得需要的最短时间。每次更新最短距离时,可以记录路径,从而确定上班路线。
状态表示$dist[i]$:
- 集合
- 所有源点是1、终点是$i$的路径的集合
- 属性:$Min$(最短路径)
- 集合
状态计算:
集合划分——$dist[i]$
$dist[i] = Min(dist[i - 1] + g[i - 1][i],dist[i - m] + g[i - m][i])$,其中$dist[i - m]$表示起点到该数下一行数的最短路径
2.2.2 算法图解
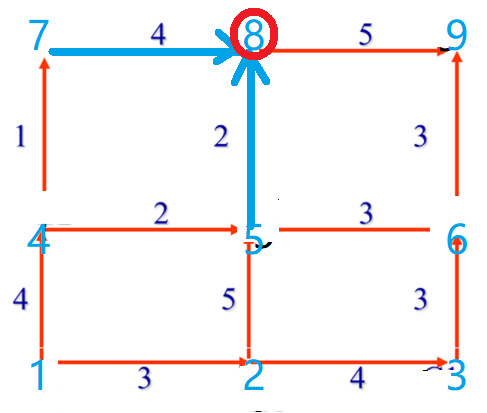
如图,蓝点标记各点的序号,每个数都是由其左边/下面的数的最短路径和其左边/下面的数到该数的距离的加和得到:
2.2.3 代码设计
void dp(int n, int m)
{
int g[N][N] = { 0 }, dist[N];
int path[N] = { 0 }, res[N];
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 读入数据(见后) ...
// 动态规划
for (int i = 2; i <= m; i++)
{
dist[i] = dist[i - 1] + g[i - 1][i]; // 对第一行的各元素,直接将路径作为答案
}
for (int i = m + 1; i <= n * m; i++)
{
if ((i - 1) % m != 0 && dist[i - 1] + g[i - 1][i] <= dist[i - m] + g[i - m][i])
{
dist[i] = dist[i - 1] + g[i - 1][i];
path[i] = i - 1; // 记录路径
}
else
{
dist[i] = dist[i - m] + g[i - m][i];
path[i] = i - m;
}
}
// 输出答案(见后) ...
cout << "需要的时间最短为:" << dist[n * m] << endl << "路径依次是:";
}2.2.4 算法复杂度分析
动态规划算法的时间代价在于遍历所有点,算法时间复杂度为$O(n)$($n$为图中所有点的数目),而空间开销主要来源于存储点、边、最短路径带来的开销。
2.3 测试结果
设图中各点依次为:
7 8 9
4 5 6
1 2 3方法1以图示方法输入:
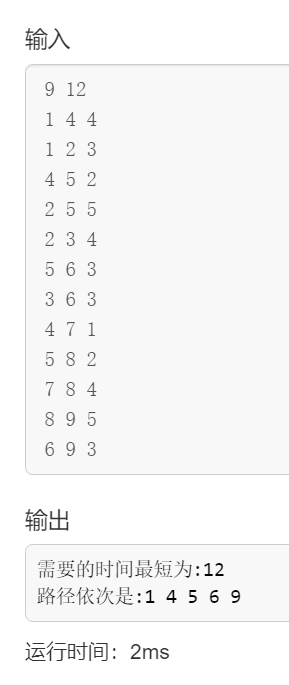
方法2以先输入行再输入列的形式输入:

多次测试,算法运行结果均正确,符合题意。
2.4 总结与讨论
我们对比以上两种算法的时间复杂度:
- 迪杰斯特拉算法:邻接矩阵$T(n)=O\left( n^{2} \right)$(其中$n=\left| V \right|$),邻接表$T(n)=O\left( n+|E|\right)$(其中$n=\left| V \right|$,$|E|$为边数)
- 动态规划算法:$T(n)=O(n)$($n$为图中所有点的数目)
通过对以上两种算法时间复杂度的比较,使用动态规划算法的时间性能是最优的。
动态规划算法主要分为几大阶段,即划分阶段、选择状态、确定决策并写出状态转移方程、写出规划方程。动态规划本质上是多阶段决策过程,最关键的是确定最优子结构,并根据上一阶段的状态和决策来导出本阶段的状态以写出状态转移方程。
我在代码设计中遇到的问题主要有:
- 动态规划算法中,确定以什么形式输入点
- 边界条件没判断正确,第一行和第一列的
dist数组需要特别判断 - 数组开始未初始化,导致调试出错
2.5 附:源代码
法1:迪杰斯特拉算法
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 510;
struct graph
{
int n, m;
int g[N][N];
};
void dijkstra(struct graph &graph)
{
bool st[N] = { 0 };
int path[N] = { 0 }, res[N] = { 0 }, dist[N] = { 0 };
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; //初始化
for (int i = 0; i < graph.n; i++)
{
int t = -1; //t为-1表示还未选择一个点
for (int j = 1; j <= graph.n; j++)
{
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j; //选取还未被选择的且距离最近的点
}
st[t] = true;
for (int j = 1; j <= graph.n; j++)
{
if (dist[j] > dist[t] + graph.g[t][j])
{
dist[j] = min(dist[j], dist[t] + graph.g[t][j]);
path[j] = t;
}
}
}
cout << "需要的时间最短为:" << dist[graph.n] << endl << "路径依次是:";
int j = graph.n, i = 0;
res[i] = graph.n; // 记录终点
while (path[j] != 0) // 将路径存放到结果数组中
{
res[++i] = path[j];
j = path[j];
}
for (int m = i; m >= 0; m--) // 逆序输出
{
cout << res[m] << " ";
}
}
int main()
{
struct graph graph;
cin >> graph.n >> graph.m;
memset(graph.g, 0x3f, sizeof graph.g);
while (graph.m--)
{
int a, b, c;
cin >> a >> b >> c;
graph.g[a][b] = min(graph.g[a][b], c);
}
dijkstra(graph);
return 0;
}法2:动态规划算法
#include<iostream>
#include<cstring>
#include<utility>
using namespace std;
const int N = 20;
void dp(int n, int m)
{
int g[N][N] = { 0 }, dist[N];
int path[N] = { 0 }, res[N];
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 读入数据
for (int i = 1; i < m * n; i++)
{
if (i % m == 0)
continue;
cin >> g[i][i + 1];
}
for (int i = 1; i <= m * (n - 1); i++)
{
cin >> g[i][i + m];
}
// 动态规划
for (int i = 2; i <= m; i++)
{
dist[i] = dist[i - 1] + g[i - 1][i];
}
for (int i = m + 1; i <= n * m; i++)
{
if ((i - 1) % m != 0 && dist[i - 1] + g[i - 1][i] <= dist[i - m] + g[i - m][i])
{
dist[i] = dist[i - 1] + g[i - 1][i];
path[i] = i - 1;
}
else
{
dist[i] = dist[i - m] + g[i - m][i];
path[i] = i - m;
}
}
// 输出答案
cout << "需要的时间最短为:" << dist[n * m] << endl << "路径依次是:";
int j = n * m, i = 0;
res[i] = n * m; // 记录终点
while (path[j] != 0) // 将路径存放到结果数组中
{
res[++i] = path[j];
j = path[j];
}
for (int m = i; m >= 0; m--) // 逆序输出
{
cout << res[m] << " ";
}
}
int main()
{
int n, m; // n代表行数, m代表列数
cout << "请输入公路矩阵行列的点数" << endl;
cin >> n >> m;
cout << "请输入各条边" << endl;
dp(n, m);
return 0;
}
