https://www.anquanke.com/post/id/231413#h3-6
Introduction
符号执行被认为是一种高效但昂贵的探索程序的技术。它通常与模糊测试(所谓的混合模糊测试)相结合,其中 fuzzer 利用启发式来快速探索相对容易到达的路径,而符号执行提供测试用例,以到达目标程序中更难以探索的部分。
符号执行系统的一个重要特征是,whether 它们是需要被测程序的源代码,or 是以黑盒方式应用于仅限二进制的程序。虽然在测试自己的产品或开源软件时,基于源代码的测试就足够了,但许多现实场景需要能够在没有源代码的情况下分析二进制文件。
Some Reasons:
- 我们越来越多地被嵌入式设备包围和依赖。它们的固件通常仅以二进制形式提供。因此,安全审计需要二进制分析工具;
- 即使在测试自己的产品时,专有库依赖关系也可能不会随源代码一起发布,从而使基于源代码的方法变得不可行的。
- 基于源代码的测试对于被测的大型程序来说可能是不切实际的。使用基于源代码的工具,通常需要以工具规定的专用方式构建所有库依赖项,这可能会给测试人员带来很大的负担。此外,如果测试中的程序是用多种编程语言混合实现的,那么基于源代码的工具很可能无法处理所有这些语言。
目前的问题:
当调用仅限二进制的符号执行器时,用户经常面临这样的困境:工具要么针对性能进行优化,要么针对体系结构独立性进行优化,但很少同时提供这两者。
QSYM展示了如何实现非常快的二进制文件符号执行,但是它通过将实现绑定到x86处理器的指令集来实现高速。这不仅使系统架构依赖,而且由于现代处理器指令集的庞大规模,它也增加了它的复杂性;用作者自己的话来说,他们的方法是“为实现复杂性付费,以减少执行开销”。S2E是一个广泛适用但执行速度相对较低的系统的例子。S2E可以从概念上分析大多数 CPU 体系结构的代码,包括内核代码。然而,其广泛的适用性需要对目标程序进行多次翻译和最终解释,这增加了系统的复杂性并最终影响性能。
事实上,在纯二进制符号分析中,高性能通常是通过高度专门化的实现来实现的——这种设计选择与体系结构的灵活性相冲突。
本文的方案:
(a)独立于被测程序的目标体系结构,(b)具有较低的实现复杂性,然而(c)实现高性能。
The key insight:
QEMU 的 CPU 仿真可以与非常轻量级的符号执行机制相结合:我们不需要将目标程序翻译成计算成本高昂的中间表示形式,然后再进行符号解释(如 S2E),而是与 QEMU 的二进制翻译机制挂钩,以便将符号处理直接编译到仿真器发射和执行的机器代码中。
这种方法在保持完全平台独立性的同时,还能获得优于最先进系统的性能。目前,我们专注于 Linux 用户模式程序(即 ELF 二进制文件),但也有可能将这一概念扩展到 QEMU 支持的任意平台的全系统仿真(例如,用于固件分析)。
与 SymCC 工作的比较:
- 将符号处理编译到目标程序的概念也是我们之前的工作
SymCC的核心,它优于目前其他的符号执行方法。 SymCC只适用于有源代码的情况,因此不支持二进制分析。相比之下,SymQEMU 演示了如何在仅二进制环境中实现类似的性能提升,并遵守该环境固有的所有额外限制(参见第二节)。
与最先进的二进制符号执行器 S2E 和 QSYM 进行了比较:
- 在随时间推移达到的覆盖率方面,SymQEMU 优于这两种执行器。
- 我们还发现 SymQEMU 的性能与
SymCC相似,尽管后者需要访问源代码。 - 我们将SymQEMU提交给了Google FuzzBench(一个 fuzzer 比较框架);尽管该测试套件并非针对符号执行系统,但在21个目标中,SymQEMU在3个目标上的表现优于所有包含在内的 fuzzer。
Contributions:
- 我们分析了最先进的二进制符号执行实现,并找出了它们各自的优缺点。
- 我们提出的方法既结合了现有系统的优点,又避免了它们的大部分缺点;其核心思想是将基于编译的符号执行应用于二进制文件的新技术。
- 我们在 Google FuzzBench 以及开源和闭源实际软件上评估了我们的系统。
Background
Symbolic Execution 概述
符号执行的总体目标是跟踪目标程序执行过程中如何计算中间值。通常,每个中间值都可以用程序输入的公式来表示。然后,在执行过程中的任何时刻,系统都可以利用这些符号表达式来回答诸如 “这个数组访问是否会越界”、”是否有可能使用程序的这个分支 “或 “这个指针在被取消引用时是否会为空 “之类的问题。
此外,如果答案是肯定的,符号执行器通常会提供一个测试用例,即触发所请求行为的新程序输入。
这种能力使得符号执行在自动程序测试中极为有用,因为自动程序测试的目标是尽可能多地探索程序的边界情况,并找到导致崩溃或引发错误的输入。
为了跟踪目标程序中的计算,符号执行系统需要对程序的指令集有一定的了解。目前的许多实现都会将程序翻译成中间表示;此类表示的典型例子有 LLVM bitcode 和 VEX。中间表示随后以符号方式执行;由于执行器只需处理中间语言(通常由数量很少的指令组成),因此实现起来相对简单。
此外,我们在以前的工作中发现,从被测程序的高级表示法导出的查询比从低级指令集(如机器码)导出的查询更容易解决。
可能原因:
高级表示更接近人类编码的思维方式,更容易理解和分析。而低级指令集则更接近计算机硬件执行的方式,更复杂和抽象,需要更深入的计算机体系结构知识来解决。因此,如果能够使用高级表示来生成查询,可以简化问题的解决过程。
将程序翻译为中间表示需要大量的计算工作,而且会给程序执行带来开销;因此,有些实现选择放弃任何形式的翻译,直接处理机器代码。除了性能上的优势外,跳过程序翻译还有助于提高鲁棒性,因为即使符号执行器不知道如何解释给定指令,具体的机器代码也能被执行。但缺点是,专门使用特定处理器架构的机器代码会将符号执行系统限制在该平台上。另一种极端情况是直接处理源代码,这种情况如今已不常见,而且显然不适用于只有二进制代码的情况。
Binary-only symbolic execution
没有源代码的情况下,将程序翻译为中间表示需要可靠的反汇编器;由于静态反汇编的挑战,大多数实现都是在运行时按需进行翻译。
此外,在没有源代码的情况下,对多种体系结构的支持变得至关重要:没有源代码,无论符号执行器支持哪种体系结构,都无法交叉编译程序【cross-compiling,指将代码从一个平台或架构编译成另一个平台或架构所需的过程】。如果符号执行系统无法处理被测程序的目标体系结构,就根本无法使用。这一点与嵌入式领域尤为相关,因为在嵌入式领域,处理器架构的多样性非常普遍。
State-of-the-art solutions
Angr
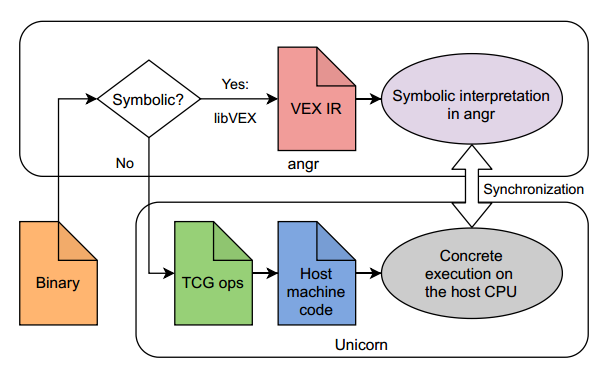
重用VEX(Valgrind框架的中间语言和翻译器)。目标程序在运行时进行翻译,符号执行器解释VEX指令。作为一种优化,angr可以在Unicorn中执行不涉及符号数据的计算(即其结果不依赖于程序输入),Unicorn是一个基于QEMU的快速CPU模拟器。
由于基于VEX, anger继承了对VEX知道如何处理的所有体系结构的支持。由于符号执行器的核心是用Python编写的,所以它相当慢,但非常通用。
S2E
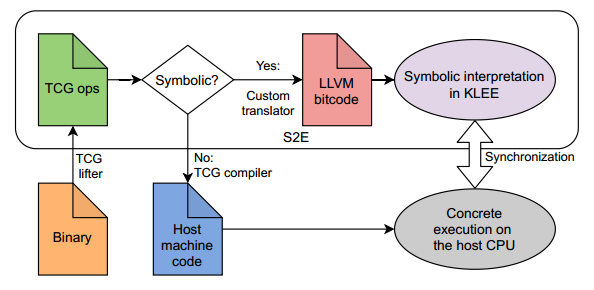
我们希望将基于源代码的符号执行系统KLEE扩展到目标程序的依赖项和操作系统内核。为此,S2E在模拟器QEMU中运行整个操作系统,并将其连接到KLEE,以便象征性地执行相关代码。
两步翻译后代码量变大以至于后续解释性能比较慢。
最终的系统相当复杂,涉及对被测程序的多次翻译:
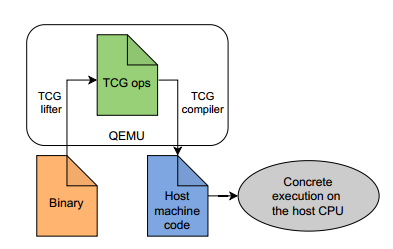
1)QEMU是一个二进制转换器,即在正常操作中,它将目标程序从机器码翻译为中间表示(称为TCG ops),然后将其重新编译为主机CPU的机器码。
2)当计算涉及符号数据时,S2E使用的修改后的QEMU不会将TCG ops重新编译为主机代码;相反,它将它们转换为LLVM位码,然后传递给KLEE。
3)KLEE对LLVM位码进行符号解释,并将结果的具体部分返回给QEMU。
这种方法产生了一个非常灵活的系统,它可以在概念上处理许多不同的体系结构,并通过操作系统的所有层跟踪计算然而,灵活性是有代价的:S2E是一个具有大量代码库的复杂系统。此外,从机器码到TCG ops再到LLVM位码的两步转换会损害其性能。与angr相比,从用户的角度来看,S2E的设置和运行更复杂,但提供了更全面的分析。
TCG ops是QEMU中使用的中间表示形式,用于将目标程序的机器代码翻译为与特定体系结构无关的形式。TCG ops是一系列指令的列表,以链表的形式存储。它不具备像基本块这样的可导航的高级结构,也无法进行较为复杂的优化。TCG ops主要关注翻译速度,因此对于程序中的符号执行支持较少,因而无法直接进行符号执行。
相比之下,LLVM位码是一种高级的中间表示形式,具备提供给编译器分析和修改的API。LLVM位码被广泛用于静态分析和优化,包括符号执行。符号执行使用LLVM位码作为输入,可以在符号层面对程序进行分析和执行。
QSYM
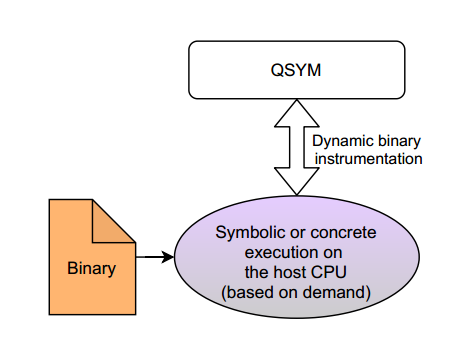
QSYM 非常注重性能,它不会将目标程序翻译成中间语言。相反,它在运行时对 x86 机器代码进行检测,为二进制文件添加符号跟踪功能。具体来说,它利用动态二进制工具框架 Intel Pin 在目标程序中插入钩子。在钩子中,它执行与程序执行的机器码指令等价的符号指令。
这种设计为 x86 程序提供了一个非常快速和强大的符号执行器。然而,该系统本质上受限于单一目标架构,而且实现起来非常繁琐,因为它需要处理相关计算中可能出现的每一条 x86 指令。在以前的工作中,我们发现 QSYM 是分析 x86 二进制程序的绝佳工具,但增加对其他架构的支持将是一项巨大的工作量。
SymCC
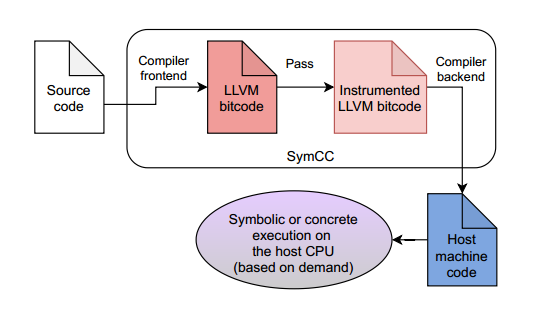
在构建 SymCC 时,我们的核心观点是大多数现代符号执行系统都是解释器。我们提出了一种基于编译的方法,并证明这种方法不仅能提高执行性能,还能提高系统的整体探索能力。
SymCC 在编译时挂钩编译器和目标代码,并注入对运行时支持库的调用。这样,符号执行就成为编译程序的一个组成部分。此外,分析代码还能从编译器的优化中获益,而且每次执行时都不会重复检测工作。
从根本上说,SymCC 基于编译的方法需要一个编译器,因此只有当被测程序的源代码可用时才适用。尽管如此,我们认为这种方法前景广阔,足以将其应用于纯二进制符号执行。本文的一个主要贡献就是证明了基于编译的符号执行实际上是如何在二进制文件中高效运行的。
SymQEMU
Design
该系统有两个主要目标:
1) 实现高性能,以便扩展到现实世界的软件;
2) 保持合理的平台独立性,也就是说,添加对处理器架构的支持不需要很大的努力。
我们发现目前流行的先进系统通常能实现其中一个目标,但不能同时实现两个目标:在介绍的系统中,S2E 和 angr 具有很高的灵活性,但在性能上却落后于其他系统,而 QSYM 虽然速度很快,但却与 x86 平台密切相关。
我们已经看到,目前与平台无关的解决方案是将被测程序翻译成中间表示法,这样,为了支持新的体系结构,只需移植翻译器即可。理想情况下,我们可以选择一种中间语言,因为许多相关架构的翻译器已经存在。以与体系结构无关的方式灵活表示程序是一种众所周知的技术,已成功应用于许多其他领域,如编译器设计和静态二进制分析。因此,我们也将其纳入了我们的设计中。虽然将程序翻译成中间表示法给我们带来了灵活性,但我们需要注意对性能的影响:静态翻译纯二进制程序具有挑战性,因为反汇编可能并不可靠(尤其是在存在间接跳转的情况下),而且在运行时执行翻译会在分析过程中产生开销。
首先,我们注意到 S2E 和 angr 的速度都受到非必要问题的影响,而这些问题可以通过工程努力加以解决:
- S2E 对被测程序进行了两次翻译。如果在第一个中间表示上执行符号执行,就可以避免第二次翻译
- Angr 的性能受到 Python 实现的影响;将核心移植到更快的编程语言可能会带来显著的提速。
然而,我们的贡献不仅仅在于发现和避免这两个问题。这也是第二个发现发挥作用的地方: S2E 和 angr 以及我们所知的所有其他只翻译二进制符号执行器都会解释被测程序的中间表示。(这与上文建议的修改无关—解释是它们设计的核心部分)。我们推测,编译目标程序的工具版本可以获得更高的性能。SymCC 最近的研究表明,基于源代码的符号执行也是如此,但其基于编译器的设计本质上需要源代码,因此不适用于纯二进制用例。
我们的方法如下:
1) 在运行时将目标程序翻译成中间语言;
2) 根据符号执行的需要对中间表示法进行工具化;(Instrument the intermediate representation as necessary for symbolic execution)
3) 将中间表示法编译成适合运行分析的 CPU 的机器代码并直接执行。
通过将机器目标程序编译为机器代码,我们弥补了首先将二进制程序翻译为中间语言所带来的性能损失:CPU 执行机器代码的速度远远快于解释器运行中间表示的速度,因此我们可以获得与非翻译系统相当的性能,同时保留了程序翻译所带来的架构独立性优势。
Implementation
我们在 QEMU 的基础上实现了 SymQEMU。它是一个强大的系统仿真器,支持大量架构。在它的基础上,我们能够实现平台独立性的目标。
S2E 也同样基于 QEMU,这大概也是出于类似的原因。但 QEMU 还有另一个特点,可以满足我们的需求,并与其他翻译器区分开来:QEMU 不仅能将二进制文件翻译为与处理器无关的中间表示法,还能将中间语言编译为主机 CPU 的机器代码。我们利用这一机制来实现第二个目标:性能。
下图为QEMU的机制。
Valgrind 框架也支持类似的机制,其作者将其称为 “反汇编-再合成“(disassemble-and-resynthesize);就我们的目的而言,QEMU 相对于 Valgrind 的主要优势在于,QEMU 可以将特定客户架构的二进制文件翻译为不同主机架构的机器代码,也可以仿真整个系统,这为未来支持跨架构固件分析的扩展奠定了更好的基础。
具体来说,我们在QEMU中扩展了一个名为Tiny Code Generator (TCG)的组件。在未修改的QEMU中,TCG负责将客户机体系结构机器代码块翻译成一种称为TCG ops的与体系结构无关的语言,然后将这些TCG ops编译为主机体系结构的机器代码。由于性能原因,翻译后的块随后会被缓存,因此每次执行只需要进行一次翻译。SymQEMU在过程中又插入了一个步骤:当被测程序被转换为TCG ops时,我们不仅发出模拟来宾CPU的指令,而且还发出额外的TCG ops来为结果构造符号表达式。
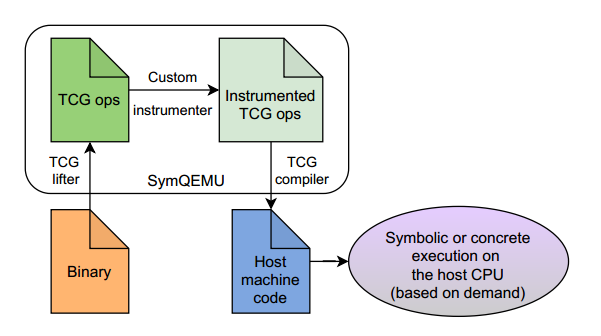
TCG 操作指令的参数排序与英特尔语法中的 x86 汇编一样,即目标是任何指令的第一个参数。上述指令执行 64 位加法运算,并将结果存储为 32 位整数。普通 QEMU 会将这些 TCG 操作翻译成主机架构的机器代码。然而,SymQEMU 会在代码转换为主机架构之前,插入额外的符号计算指令:
movi_i64 tmp12_expr, $0x0
movi_i64 tmp12, $0x2a
call sym_add_i64, $0x5, $1, tmp2_expr, rax, rax_expr, tmp12, tmp12_expr
add_i64 tmp2, rax, tmp12
movi_i64 tmp12, $0x4
call sym_zext, $0x5, $1, rsi_expr, tmp2_expr, tmp12
ext32u_i64 rsi, tmp2每个代码块都与 QEMU 最初生成的 TCG 操作之一相对应;事实上,每个代码块的最后一条指令都与相应的原始指令完全相同。在第一个代码块中,我们将常量 42 的表达式设置为 null(即声明该值为具体值)。在第二个代码块中,辅助函数 sym_add_i64 创建了一个表示两个 64 位整数相加的符号表达式(使用了与函数输入相对应的表达式 rax_expr)。最后,最后一个代码块调用参数为 4 的辅助函数 sym_zext,创建一个表达式,将加法结果转换为 4 字节(即 32 位)数量。最重要的是,SymQEMU 在翻译时不会执行任何这些对支持库的调用(就像解释器那样)—它只会发出相应的 TCG 操作,并依靠常规的 QEMU 机制将其翻译为机器代码。这样,就能用本地机器代码构建符号公式,而不会产生与解释中间语言相关的开销。
对于构建符号表达式并对其进行查询的支持库,我们重新使用了 SymCC 的代码,而 SymCC 又是基于 QSYM 的。这样做的好处,除了让我们不必重新实现 QSYM 中运行良好的代码外,还消除了评估中的噪音源:由于 SymQEMU 和 QSYM 使用相同的逻辑来构建和简化表达式,并与求解器进行交互,因此我们可以确保观察到的性能差异并非源于这些orthogonal design。
Platform independence
我们从一开始就指出,支持多种 CPU 架构是 SymQEMU 的一个重要目标。因此,我们现在将详细研究我们的系统在多大程度上实现了这一目标。(SymQEMU 的第二个设计目标—性能—将在第四部分通过实验加以验证)。
首先,重要的是要区分运行分析的计算机(通常称为主机)的体系结构和被测程序的编译体系结构(QEMU 术语中的客体)。特别是在固件分析中,主机和访客架构最好是不同的—被测固件所运行的嵌入式设备可能缺乏计算能力,无法以合理的速度执行符号分析,因此人们通常会在功能更强大的机器上运行符号执行器(以及一般情况下的任何固件测试)。SymQEMU 为这种使用情况做好了充分准备: QEMU 可在所有主要主机架构上运行。
对于客户架构,SymQEMU 利用 QEMU 的 TCG 转换器,该转换器覆盖了广泛的处理器类型目前列出了 22 种平台,包括 x86、ARM、MIPS 和 Xtensa,每种平台都包含多种处理器类型。此外,我们的修改几乎完全独立于目标平台。
Comparison with previous designs
与anger和S2E一样,SymQEMU遵循在中间表示级别实现符号处理的传统方法,这大大降低了实现的复杂性。然而,与这两者相比,SymQEMU执行基于编译的符号执行,允许它实现更高的性能(参见第四节)。
与QSYM相比,SymQEMU的设计最重要的优点是在保持高执行速度的同时具有架构灵活性。在QEMU之上构建使它能够从模拟器支持的大量平台中获益。
SymCC虽然不能分析二进制文件,但它与SymQEMU共享基于编译的方法。两者都通过修改中间表示将符号处理插入目标程序,并且都将结果编译成可以有效执行的机器码。然而,SymCC本质上是设计在编译器中工作的,而SymQEMU解决了在纯二进制符号执行中遇到的不同挑战(参见第II-B节):SymCC在(基于源代码的)编译期间使用LLVM位码,SymQEMU在动态二进制翻译期间使用TCG ops。参见第III-F节,了解在动态二进制翻译器上工作的特定挑战。
Memory Management
在任何合理的程序中,中间结果要么会对控制流产生影响,要么会成为最终结果的一部分—在前一种情况下,相应的表达式会被添加到路径约束集中,因此无法清理;而在后一种情况下,表达式会成为最终结果描述中的子表达式。
符号表达式怎么会变成不需要的呢?关键在于,程序输出在概念上是程序结果的一部分,但它可能在执行结束前就已产生。例如,一个归档工具会列出一个归档文件的内容,并逐个打印文件名:在每一个输出产生后,程序都可以删除相关的字符串数据,而 SymQEMU 则应清理相应的符号表达式。否则,表达式会不断累积,在最糟糕的情况下,会耗尽所有可用内存。理想情况下,我们会在符号表达式最后一次使用后将其删除。
为此,我们重用了 QSYM 的后端,它采用了 C++ 智能指针。然而,在我们的 QEMU 修改版中,我们无法轻易采用同样的方法:作为我们执行机制核心的 QEMU 组件 TCG 是一个动态翻译器,出于性能原因,它不会对翻译后的代码进行任何广泛的分析(与静态编译器不同,静态编译器通常会收集大量与变量作用域和生命周期相关的信息)。因此,很难有效地确定在翻译后的程序中插入清理代码的正确位置。
我们选择了一种基于表达式垃圾收集器的乐观清理方案: SymQEMU 会跟踪从后台获取的所有符号表达式,如果它们的数量过多,就会触发收集。核心观察结果是,通过扫描(1)模拟 CPU 的符号寄存器和(2)内存中存储与符号内存内容相对应的符号表达式的阴影区域(后端知道这两个区域),可以找到所有有效表达式。在枚举出所有有效表达式后,SymQEMU 可以将得到的表达式集与曾经构建的所有表达式集进行比较,并释放那些不再有效的表达式。特别是,当程序从寄存器和内存中删除计算结果时(如上文归档器的例子),相应的表达式就不再被视为有效表达式,因此会被释放。我们已将表达式垃圾回收器与 QSYM 基于智能指针的内存管理连接起来—这两种机制都需要在表达式被释放前确认其已被闲置。
Modifying TCG ops
我们的方法基本上需要能够将新的指令插入到表示目标代码的TCG操作列表中。然而,TCG并不打算在翻译期间允许这种广泛的修改——作为一种动态转换器,它更加注重速度。因此,TCG几乎没有支持对TCG操作进行程序化编辑的功能。例如,LLVM提供了一个广泛的API,用于编译器传递检查和修改LLVM位码,而TCG只是在一个平坦的链表中存储指令,没有类似基本块的可导航的高级结构。此外,在一个转换块内,控制流程应该是线性的(只有非常有限的例外),从而排除了像SymCC嵌入式具体性检查的优化。
为了尽量减少与TCG基础设施的冲突,我们在生成目标指令时为每个目标指令都发出了符号处理。虽然这可以避免TCG的优化器和代码生成器的问题,但它使得高级静态优化变得不可行,因为我们只能逐个指令地查看代码。特别是,我们几乎没有机会在静态环境下确定一个临时值是否是具体的。类似地,如果所有操作数在运行时都是具体的,我们无法直接跳过符号计算来发出跳转指令。代替的,我们达成了一种折中方案,它考虑了TCG的操作环境的限制(特别是需要快速动态翻译的需求),同时仍然允许我们实现相对较高的执行速度:我们在支持库中执行具体性检查。通过这种方式,当输入是具体的时候,我们仍然可以跳过符号计算,但是检查会增加额外的库调用的开销。
我们将具体性检查的逻辑实现为一个独立的代码库(或函数)。具体性检查是指在运行时判断一个变量或值是否具体(即常量)的操作。通过将具体性检查的代码放在支持库中,我们可以在需要的时候调用这个库来执行具体性检查。

