1 绪论
程序+安全属性 提供普适框架(简单语言) 求解算法
执行由符号执行引擎执行,它为每个探索的控制流路径维护:
(i)一个一阶布尔公式,描述沿该路径采取的分支所满足的条件;
(ii)一个将变量映射到符号表达式或值的符号存储器。分支执行更新公式,而赋值更新符号存储。
路径条件 $PC_1 = (x + y > 0)$
符号存储器不变 $S_1 = \{ x \mapsto x, y \mapsto y, z \mapsto x + y \}$
返回 $z$ 的符号表达式,即 $x + y$
分支执行更新公式,而赋值更新符号存储。
基于可满足模理论(SMT)解算器进行验证
符号执行挑战
- 健全性(Soundness):保证找到所有可能的不安全输入【防止假阴性】;
- 完备性(Completeness):认为不安全的输入实际上是不安全的【防止假阳性】
挑战:
- 内存:如何处理指针、数组及其他复杂对象
- 环境:如何处理跨软件栈的交互,如调用库代码/系统代码(创建文件、回调用户代码……)
- 状态空间爆炸
- 约束求解:非线性算法结构(这里不考虑)
2 符号执行引擎
经典符号执行的限制:
- 它无法探索可能导致无法处理的路径约束的可行执行;
- 实际的程序通常不是自包含的:实现一个能够静态分析整个软件堆栈的符号引擎可能相当具有挑战性,因为在执行期间很难准确评估任何可能的副作用。
解决上述问题并使符号执行在实践中可行的一个基本思路是将具体执行和符号执行相结合:这被称为“共融执行”(concolic execution,具体执行和符号执行相结合)。
动态符号执行
用具体执行驱动符号执行,除符号存储和路径约束外,引擎维护一个具体存储 $\sigma_{c}$。
选择任意输入作为开始,同时更新两个存储和路径约束来具体/符号执行程序。具体执行采用的分支将同样被符号执行指向
符号执行由特定的具体执行驱动->符号执行不需要调用约束求解器决定分支条件是否(不)可满足(由具体执行直接测试)
为了探索不同路径,可以否定一些分支给出的路径约束,生成新输入(调用SMT求解器为新约束找到满足的分配)
由于具体执行中未遍历到的分支集合可能非常大,采用有效的启发式搜索方法可以发挥很大作用。
深度优先策略选择要否定的分支(e.g. DART) 黑盒
分代搜索(e.g. SAGE) 白盒
将搜索过程划分为多个”世代”(generations),每个世代通过选择、变异和交叉等操作来产生新的测试用例

(b)由于不清楚a和x的关系,需要随机,可能导致部分路径没有被执行;(c) 该函数不会触发错误语句,但由于未跟踪的abs语句,导致引擎无法检测(路径发散【符号执行过程中,生成的输入预期会引导程序执行特定路径,但实际执行时却走了不同的路径】)
存在假阴性(由于路径覆盖不足等引起的未能发现程序某些缺陷)和路径分歧
选择性符号执行
函数A调用函数B,在调用点执行模式发生变化的两种情况:
(1)从具体到符号再返回;【B的论证是符号化的,B是符号化的。B也被具体地执行,它的具体结果返回给A,然后A又具体地恢复】
(2)从符号到具体再返回。【B的参数被具体化,B被具体执行,执行在a中象征性地恢复】
可能存在漏支等导致假阴性,收集软约束并检查返回后的分支是否使软约束无效。
在分析复杂代码段时,某些部分可能更适合符号化处理,以捕获所有可能的执行路径和边界情况。具体执行模式能够高效处理大部分代码,但对某些关键段落,符号执行可以更全面地探索不同路径和状态。
路径选择
DFS / BFS / 随机路径选择(根据路径的长度和分支度为路径分配概率,倾向于探索次数较少的路径,防止环路和其他路径爆炸因素导致的饥饿,e.g. KLEE)
子路径引导搜索(启发式方法):子路径定义为长度为n的完整路径的连续子序列,值n很重要。
尝试根据某个目标对可能通向感兴趣状态的路径进行优先排序(e.g. AEG):
漏洞路径优先策略选择:其过去的状态包含小但无法利用的漏洞,选择其;
循环耗尽策略探索访问循环的路径:循环可能导致缓冲区溢出漏洞,通过耗尽循环的所有可能路径来发现潜在漏洞;
优先考虑识别符号地址的内存访问或检测符号指令指针的路径(e.g. Mayhem);
利用有限状态机(FSM)表示的属性,利用动态计算方法进行数据流分析(
Preset已经达到的状态&Postset将达到的状态,计算交集);适应度函数测量探索路径和实际目标测试覆盖率之间的距离

适应度函数为 $|110-x|$

根据复合适应度值增益,决定分支节点翻转:
$F(P) - FGain(b)$,其中 $F(P)$ 为 $P$ 的适应度值,$FGain(b)$ 为 $b$ 的适应度增益。
如
Path4中line2复合适应度最低,翻转为最高优先级。【首先判断路径的适应度值:最差、20、19、19、18,将一个假分支翻转,得出适应度增益(Path4的line2复合适应度值为18 - 1)
符号向后执行(SBE)
从目标点到程序入口点进行探索
目的通常是识别一个测试输入实例,该实例可以触发特定代码行的执行(例如,assert 或 throw 语句)
变体(调用链向后符号执行(CCBSE)):确定目标行所在函数的有效路径。引擎移动到包含目标点的函数的调用者之一,重建从调用者的入口点到目标点的有效路径,重构出程序主函数的有效路径。CCBSE从目标点向后遵循调用链,但在每个函数内部都像传统的符号执行一样进行探索。
SBE和CCBSE的关键要求是过程间控制流图的可用性,挑战:
(i)构建图具有挑战性;
(ii)一个函数可能有多个调用点,探索代价高
符号执行器的设计原则
设计原则:
- 进度(Progress):内存消耗问题很关键
- 避免工作重复(Work repetition)
- 分析结果重用,避免在先前解决的路径约束上对SMT求解器进行代价高昂的调用
试图在一次运行中同时执行多个路径的符号执行程序(也称为联机)克隆每个依赖输入的分支的执行状态。(e.g. KLEE, AEG, $S^2E$)
问题:
- 许多活动状态需要保存在内存中,并且内存消耗可能很大,这可能会阻碍进程。减少内存占用的有效技术包括写时复制(copy-on-write),它尝试在不同状态之间尽可能多地共享。
- 并行执行多个路径需要确保执行状态之间的隔离,例如,通过模拟系统调用的效果来保持操作系统的不同状态。
离线执行器(e.g. SAGE)每次只分析一条路径,称混合符号执行(concolic execution)。它与在线执行器相比有以下特点:
- 低内存消耗:每次只执行一条路径,避免了同时保持多个活跃状态的需求,从而显著降低了内存消耗。
- 独立执行:每条路径独立运行,能够立即重用先前运行的分析结果。
- 重复工作
离线执行器的典型实现步骤:
- 具体执行和输入种子:离线执行器首先需要一个输入种子,这个种子用于具体执行(concrete execution)。具体执行是指按照特定的输入,逐步执行程序,并记录每一步的指令执行情况。
- 指令跟踪:在具体执行过程中,记录一条指令跟踪(trace of instructions),这是一系列按照顺序执行的指令。
- 符号执行:然后,离线执行器对记录的指令跟踪进行符号执行。这意味着它会重新执行这些指令,但这次使用符号变量代替具体值,从而探索不同的可能路径。
混合执行器(Hybrid executors, e.g. Mayhem)尝试在速度和内存需求之间取得平衡,结合了在线和离线执行器的特点。其工作方式如下:
- 在线模式开始:混合执行器首先在在线模式下开始运行,尝试同时执行多个路径,并在每个输入依赖的分支处克隆执行状态。
- 生成检查点:当内存使用或并发活跃状态的数量达到阈值时,不再创建新的执行器,而是生成检查点(checkpoints)。检查点包含当前的符号执行状态和重放信息。
- 恢复和重放:当需要恢复检查点时,从检查点中恢复具体状态,并从恢复的具体状态重新开始在线探索。这种方法避免了创建过多的执行器,从而控制了内存消耗,同时也能在需要时恢复并继续探索。
3 内存模型
符号执行的一个关键方面是如何对内存进行建模以支持带有指针和数组的程序。这需要扩展我们的内存存储概念,不仅映射变量,而且映射到符号表达式或具体值的内存地址。
一般来说,显式地对内存地址建模的存储 $σ$ 可以被认为是将内存地址(索引)与具体值或符号值的表达式相关联的映射。
我们仍然可以通过在映射中使用变量的地址而不是名称来支持变量。
若 $v$ 是一个数组,$c$ 是一个整数常数,那么 $v[c]→e$ 意为 $\&v + c→e$
当操作中引用的地址是一个符号表达式时,就会出现符号内存地址问题(the symbolic memory address problem)。
完全符号记忆
状态分叉(State forking):如果一个操作读取或写入一个符号地址,则通过考虑该操作可能导致的所有可能状态来分叉状态。
if - then - else公式:
设 $α$ 是一个符号地址,它具有具体值 $a_1, a_2,…$:
- 从 $α$ 读取得到表达式 $ite(α = a_1, σ(a_1),ite(α = a_2, σ(a_2),…));$
- 在 $α$ 中写表达式 $e$ 更新符号存储为每个 $a_1, a_2,…$,如 $σ(a_i)←ite(α = a_i, e, σ(a_i))$

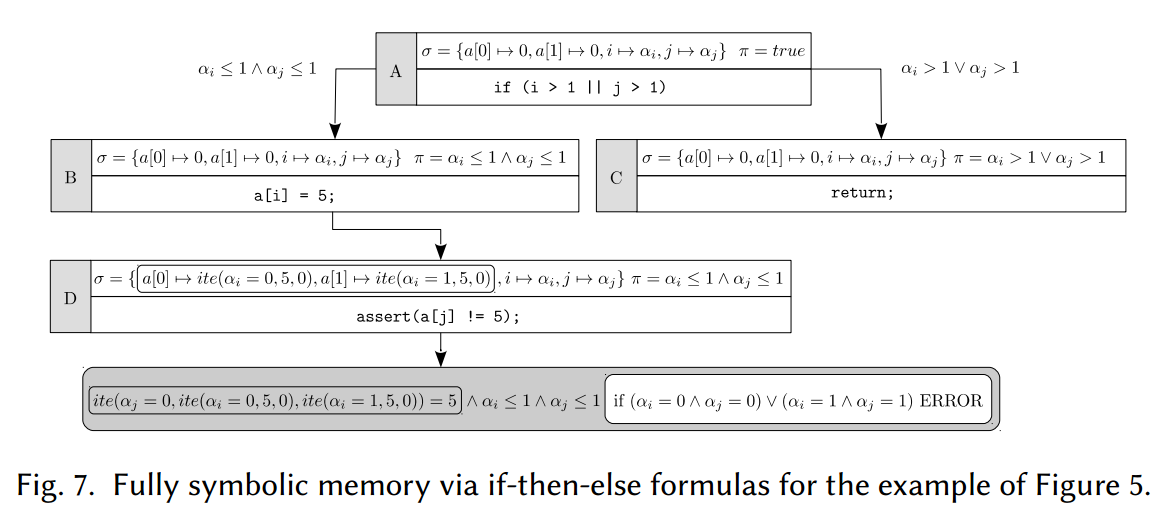
然而,符号地址可以引用内存中的任何单元,导致可能状态数量的难以处理的爆炸。由此设计技术来提高可伸缩性(scalability):
- 以紧凑形式表示内存:利用分页区间树实现
- 用稳健性换取业绩(Trading soundness for performance):e.g. 通过用具体地址替换符号指针,将符号探索限制在执行状态的子集中
- 堆建模:将探索限制在指针被限制为NULL或指向先前堆分配对象的状态,而不是指向任何通用内存位置(Section 3.2 & 4)
地址具体化
具体化在离线执行器中突出的例子是DART和CUTE,它们通过将 $T^*$ 类型的引用具体化为NULL或新分配的 $sizeof(T)$ 字节对象的地址来处理内存初始化。
DART随机做出选择,而CUTE首先尝试NULL,然后在随后的执行中尝试一个具体地址。若 $T$ 是一个结构体,CUTE会递归地对指针对象的所有字段进行同样的具体化处理。
【待】由于内存地址(例如,由 malloc 返回)可能在不同的具体执行中不确定地发生变化,因此CUTE在符号公式中使用逻辑地址来保持不同运行之间的一致性。具体化的另一个原因是由于约束求解的效率:例如,CUTE只使用等价图来解释指针相等约束,而对于需要昂贵的SMT理论的更一般的约束则诉诸具体化。
部分内存建模
分别存在的问题:
- 具体化(稳健性丧失,丧失一些符号执行的灵活性,因为它只能处理具体值,无法捕捉到所有可能的程序行为)
- 符号化(可扩展性问题,全符号内存模型需要维护的符号内存状态急剧增加,导致内存使用量和计算复杂度大幅上升)
关键思想是,如果可能值的连续间隔足够小,写地址总是具体化的,读地址是符号化的。
可能假设的可能值集的基本方法是尝试不同的具体值并检查它们是否满足当前路径约束,在每次尝试中排除大部分地址空间,直到找到一个较小的范围。
优化:值集分析(value-set analysis,尝试不同的具体值并检查它们是否满足当前路径约束,来逐步缩小可能值集的范围)和查询缓存的形式(Section 6)
延迟初始化
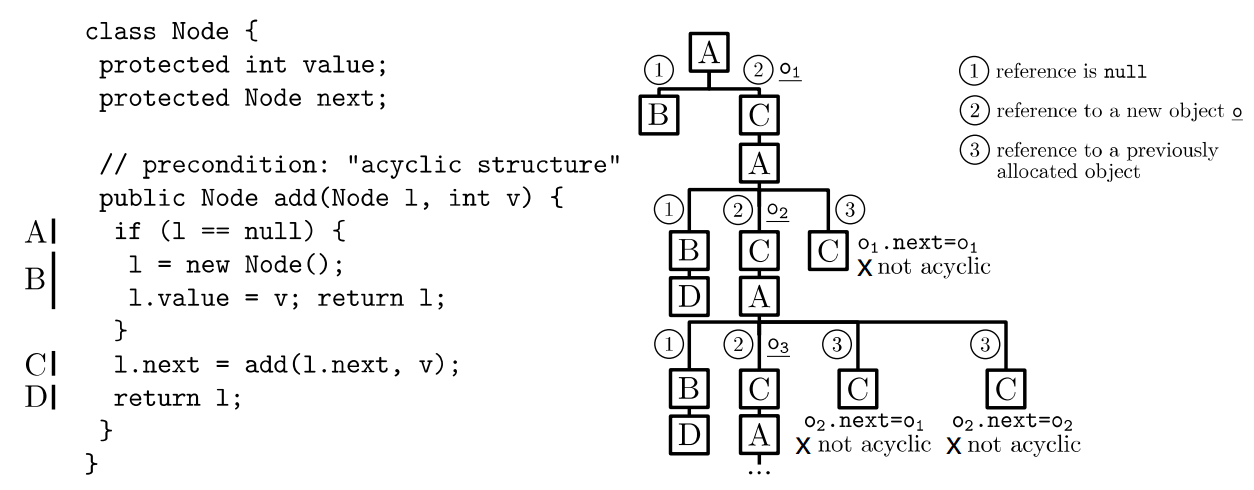
一方案通过引入延迟初始化来有效地处理动态分配的对象,从而泛化了符号执行。
状态表示被扩展为用于维护这些对象的堆配置。以复杂对象作为输入的方法的符号执行从未初始化的字段开始,并以惰性方式为它们赋值,即,在执行期间第一次访问时初始化它们。
当访问一个未初始化的引用字段时,算法用三种不同的堆配置分叉当前状态,其中字段分别被初始化为:
- NULL
- 对具有所有符号属性的新对象的引用
- 先前引入的所需类型的具体对象
一方法将延迟初始化与用户提供的方法先决条件相结合,即在方法执行之前假定条件为真。前提条件用于描述那些程序输入状态,在这些状态中,方法按照程序员的预期运行。例如,我们期望二叉树数据结构是非循环的,并且每个节点(除了根节点)都只有一个父节点。使用保守的前提条件来确保在初始化期间消除不正确的堆配置,从而加快符号执行过程。
最新的研究:提高生成堆配置的效率
- 引用变量的具体化被推迟到实际访问该对象时;
- 通过使用来自已经具体化的字段的信息,采用绑定细化来去除无兴趣的堆配置,而SAT求解器用于检查给定配置是否具有声明性前提条件,而不是原始算法中的命令式前提条件。
4 与环境的交互
由于大多数程序不是自包含的,符号引擎必须考虑它们与周围软件堆栈的频繁交互。
系统环境
早期工作(e.g. DART, CUTE, EXE)通过实际执行外部执行(使用具体参数),将系统环境包括在分析中。
- 限制探索的行为
- 在在线执行器中,可能导致来自不同执行路径的外部调用相互干扰。由于没有跟踪每个外部调用的副作用的机制,因此存在状态不一致的潜在风险(e.g. 一个执行路径可能正在读取文件,而另一个执行路径正在试图删除它)
方案:
- 创建捕获交互的抽象模型(e.g. KLEE)。每个执行状态都通过一个基本的符号文件系统来支持符号文件,该系统由一个包含
n个符号文件的目录组成,这些文件的数量和大小由用户指定。对符号文件的操作导致分叉n + 1个状态分支:每个可能的文件一个,加上一个可选的用于捕获操作中意外错误的分支。由于标准库中的函数数量通常很大,并且为它们编写模型成本高昂且容易出错,因此模型通常在系统调用级别而不是库级别实现。 - AEG对大多数可能被攻击者用作输入源的系统环境进行建模(定制化模型),包括文件系统、网络套接字和环境变量。此外,还模拟了70多个库和系统调用,包括与线程和进程相关的系统调用,以及用于捕获潜在缓冲区溢出的常用格式化函数。
若系统发生变化,建模会过时,需要被分析的程序在探索多条路径时与真实环境交互。$S^2E$在与实际环境交互时采用虚拟化来防止副作用在独立的执行路径上传播。
- 符号执行:通过
x86-to-LLVM lifter,QEMU将程序的指令转换为LLVM IR,然后KLEE对这些指令进行符号执行,探索不同的执行路径。 - 虚拟化隔离:在这个过程中,$S^2E$ 利用QEMU的虚拟化能力,确保每个分支路径在独立的环境中执行,防止副作用在不同路径之间传播。例如,当遇到
if (x > 0)时,$S^2E$ 会创建两个并行的执行实例,一个探索x > 0为真的路径,另一个探索x <= 0的路径。
- 符号执行:通过
DART目标是实现自动化单元测试。DART将C程序中引用的所有外部变量和函数以及顶级函数的参数视为外部接口。通过不确定地返回其指定返回类型的任意值来模拟外部函数。为了允许对不依赖于环境的库函数进行符号探索,用户可以调整外部和非外部函数之间的边界,以调整符号分析的范围。
应用环境
讨论处理代表被分析程序执行控制和数据流的软件元素的可能解决方案。这个问题的实例出现在像Swing和Android这样的框架中,它们体现了在用户交互期间调用应用程序代码的抽象设计(例如,通过回调)。
对于运行在托管运行时的应用程序,例如,在调用本机Java方法或 .net中的非托管代码时,符号值也会在分析边界之外流动。这些特性使引擎的实现变得复杂:例如,Java中的本机方法和反射依赖于底层JVM的内部机制。
与系统环境建模类似,早期的工作(e.g. DART, CUTE),通过使用具体的参数来执行对其他软件组件的调用。这可能导致不完整的探索,无法为可行的程序路径生成测试输入。
外部简单行为的实现通常很复杂,因为它必须考虑可扩展性和可维护性,或者可能包含与探索无关的细节,例如如何显示触发回调的按钮。
方案:
- 人工干预
- 尝试自动生成模型
- 程序切片通过静态分析工具提取相关代码片段,适用于需要手动或半自动建模的场景;
- 程序合成(program synthesis)通过自动生成等效代码模型,适用于抽象和复杂的设计模式和框架。两者结合使用,可以显著提高符号执行在处理复杂软件系统时的准确性和效率。
5 路径爆炸
路径爆炸的主要来源是循环和函数调用。循环的每次迭代都可以看作是 if-goto 语句,导致执行树中的条件分支。
若循环条件涉及一个或多个符号值,则生成的分支的数量可能是无限的,如下面的示例所示。
int x = sym_input (); // e.g. read from file
while (x > 0) x = sym_input ();sym_input() 是一个外部例程,它与环境交互(例如,通过从网络读取输入数据)并返回一个新的符号输入。在任何最终状态下设置的路径约束形式为:
$\pi=\left(\bigwedge_{i \in[1, k]} \alpha_{i}>0\right) \wedge\left(\alpha_{k+1} \leq 0\right)$
其中 $k$ 是迭代次数,$α_i$ 是 sym_input() 在第 $i$ 次迭代时产生的符号。
虽然将循环探索绑定到有限数量的迭代是简单的(并且确实是常见的),但使用这种方法很容易错过有趣的路径。
下面的技术用于优化。
修剪不可实现的路径
减少路径空间的第一个自然策略(路径约束的急切求值,eager evaluation of path constraints)是在每个分支上调用约束求解器,修剪不可实现的分支:如果求解器可以证明分支的路径约束给出的逻辑公式是不可满足的,那么程序输入值的任何赋值都不能驱动对该路径的实际执行,它可以被符号引擎安全地丢弃而不影响可靠性。Section 6讨论惰性求值。
- 正交方法:减少需检查的路径数量
- 原理:SMT求解器可用于一次探索一个大的搜索空间中的一条路径,但它最终往往会对由许多路径共享的控制流进行推理。
- 通过从每条被证明是不可满足的路径中提取最小的
unsat核心 来利用这一观察结果,在保留不可满足性的同时删除尽可能多的语句。因此,引擎可以利用unsat内核来丢弃共享相同(unsatisfiable)语句的路径
函数和循环总结(Function and Loop Summarization)
函数摘要
在整个执行过程中,可以在相同的调用上下文或不同的调用上下文中多次调用函数。
动态生成摘要:
对于给定的约束理论 $T$,定义函数总结 $\phi_{f}$,可以通过连续迭代计算,定义为 $\phi_w$ 的析取。通过 $\phi_{w}$ 捕获函数调用的结果,其中 $\phi_{w}=\operatorname{pre}_{w} \wedge \text { post }_{w}$,其中分别为输入、输出约束的结合。
循环摘要
早期work中,循环通过在迭代中添加固定的次数来更新符号变量,不能处理嵌套循环或多路径循环(主体内带有分支的循环)。
Proteus总结多路径回路的通用框架:
根据路径条件下值的变化模式(是否更新归纳变量)和循环内路径的交错模式(是否存在规律性)对循环进行分类。其利用一种扩展形式的控制流图,然后用它来构造一个对交错建模的自动机。以深度优先的方式遍历自动机,并为其中所有可行的跟踪构造析取摘要,其中跟踪表示循环中的执行。
引入压缩技术,其中对控制流图中的循环路径的分析产生模板,这些模板声明性地描述了由一部分代码生成的程序状态,作为紧凑的符号执行树。通过利用模板,符号执行引擎可以大大减少程序状态的数量。缺点是模板在路径约束中引入量词,增加求解器的负担
路径包容(Subsumption)与等价
一个大的符号状态空间为探索路径相似性的技术提供了空间,例如,放弃不能导致新发现的路径,或者在有利可图的时候抽象掉差异。
插值(Interpolation)
符号执行可以受益于插值技术,从没有显示期望属性的程序路径中派生属性,从而防止探索同样不满足它的类似路径。
插值技术能够简化路径条件,优化状态空间划分。
给定一个不可满足公式 $P \wedge Q$ 的反驳证明(refutation proof),可以构造一个逆内插 $I$ ,使得:
- 蕴涵关系: $P \rightarrow I$ 有效(即 $P$ 蕴涵 $I$ );
- 不可满足性: $I \wedge Q$ 不可满足(即 $I$ 和 $Q$ 不可能同时为真)。
包含插值(Subsumption with Interpolation)
后条件符号执行:
- 其中程序位置用后条件注释,即最弱的先决条件总结了先前探索的路径后缀。这里的直觉是,插值越弱,它就越有可能实现路径包容(约束小)。后置条件是从完全探索的路径逐渐构建的,并向后传播。当遇到分支时,相应的后置条件被否定并添加到路径约束中,如果路径被先前的探索所包含,则该后置条件将变得不满足。
路径选择策略在实现插值构建中的作用:
- DFS非常方便,因为它允许快速地全面探索路径,从而可以构建插值并最终向后传播;
- BFS阻碍了包容,因为在检查分支冗余时可能无法使用插值,因为类似的路径尚未完全探索。
无限循环(Unbounded Loops)
设计一种迭代深化策略,将循环展开到一个固定的深度,并尝试计算循环不变的插值,这样它们就可以用来证明无界情况下错误节点的不可达性。但是,对于需要析取循环不变量的程序,此方法可能不会终止。
包含抽象
【待】符号状态是根据符号堆和标量变量的一组约束来定义的。提出了一种通过图遍历匹配堆配置的算法,同时使用现成的求解器对标量数据的包容进行推理。
路径分区
控制流和数据流的依赖性分析揭示了可以在探索过程中使用的任意关系,以过滤掉无法显示其他程序行为的路径。
- 将concolic执行的输入划分为互不干扰的块,符号探索每个块,而其他块则固定为具体值。当两个输入共同影响一个语句或通过控制或数据依赖关系链接的语句时,就会发生两个输入的干扰。
- 侧重于输出,如果两条路径相对于程序输出具有相同的相关切片,则将它们放置在同一分区中。相关的切片是动态数据和控制依赖关系的传递闭包,以及涉及由于不执行而影响输出的语句的潜在依赖关系。
- 通过为单个语句构建相关切片来探索与输出无关的错误,捕获如何从符号输入中计算它们。依赖性分析有效地检查片的等价性,当所有语句实例的片都被以前的路径覆盖时,认为路径是冗余的。
欠约束符号执行
避免路径爆炸的一种可能方法是将要分析的代码(比如一个函数)从它的封闭系统中剥离出来,并单独检查它。使用用户指定的前提条件的延迟初始化(第3.4节)遵循这一原则,以便自动重建复杂的数据结构。
然而,从应用程序中取出一个代码区域可能相当困难,因为它与周围的环境相互交织;在单独分析的函数中检测到的错误可能是假阳性,因为当函数在完整程序的上下文中执行时,输入可能永远不会假设某些值。一些先前的工作,首先孤立地分析代码,然后使用具体执行测试生成的崩溃输入,以过滤掉误报。
符号引擎自动标记数据为约束不足:
- 符号执行引擎能够自动化地处理内存访问,它通过监控程序对内存的读写操作,识别哪些数据是未初始化或未被约束的。这样可以自动将这些数据标记为约束不足(即未受到具体值的约束),不需要人为的手动干预或设定。
举例说明:
- 原文:例如,当对位于堆栈上的未初始化数据执行内存读取时,可以检测到函数的输入。
- 解释:一个具体的例子是,当程序试图读取堆栈上未初始化的数据时,符号引擎可以检测到这是一个函数的输入。在这种情况下,符号引擎会将这个输入标记为约束不足的变量,因为它在函数调用之前没有被赋予任何具体的值。
约束不足的变量在符号执行中和完全约束的变量一样处理,这意味着它们在符号引擎中具有相同的基本操作和语义。然而,当这些约束不足的变量用于某些特定表达式时,可能会引发错误。例如,如果一个约束不足的变量被用于除法操作中,它可能会引发除以零的错误。这是因为符号引擎不知道这个变量的具体值,所以无法避免这种情况。
当任何表达式同时涉及未充分约束的值和完全约束的值时,必须在变量之间传播标记。例如,形式a > b的比较,其中a是受限的,而b不是,强制引擎将标记从a传播到b,类似于在处理受污染值时的污染分析。符号引擎通常使用影子内存跟踪标记。
利用前提条件和输入特征
减少路径爆炸的另一种方法是利用某些输入属性的知识。
预条件符号执行(e.g. AEG):
将探索引导到满足先决条件谓词的输入空间子集来减少探索状态的数量,关注可能导致程序某些行为的输入
该方法不是从一个空路径约束集开始,而是在初始π中添加先决条件,以便其余的探索将跳过不满足条件的分支。虽然在初始化时向π添加更多约束可能会增加求解器的负担,因为需要在每个分支上执行更多的检查,但由于更小的状态空间,这可能在很大程度上被性能收益所抵消。
符号执行中考虑的常见前提条件:
- 已知长度(即缓冲区的大小是已知的)
- 已知前缀(即缓冲区有已知前缀)
- 完全已知(即缓冲区的内容是完全具体的)
扩展循环符号执行(loop-extended symbolic execution):能够在提供输入程序描述的语法的情况下有效地探索循环。通过将迭代次数与程序输入的特征相关联,这种技术可以有效地引导由循环生成的程序状态的探索,从而减少路径爆炸问题。
状态合并
一个合并的状态是由一个公式来描述的,这个公式代表了公式的分离,如果它们保持分离,这些公式将描述单个状态。与抽象解释等其他静态程序分析技术不同,符号执行中的合并不会导致过度逼近。
早期的研究工作表明,路径合并技术能够有效减少需要探索的路径数量,从而提高符号执行的效率。然而,这些合并操作会增加约束求解器的负担,特别是当合并操作引入了析取(disjunction)时,约束求解器的性能可能会受到影响。析取是指在逻辑表达式中使用“或”操作符,将多个条件组合在一起,这种情况会使求解过程变得更加复杂和耗时。
路径合并技术在某些情况下可能会引入新的符号表达式。例如,在条件赋值语句中,合并不同的具体值时,会将这些具体值转化为基于条件的符号表达式。这种操作虽然减少了路径数量,但也增加了符号表达式的复杂性。
静态状态合并通常以精度换取可伸缩性,如通过只展开一次循环。
启发式方法合并
实际上,生成更大的符号表达式和可能额外的求解器调用可能会超过具有更少状态的好处,从而导致更差的整体性能。
- 查询计数估计:依赖于简单的静态分析,以确定每个变量在CFG(控制流图)中任何给定点之后的分支条件中使用的频率。该估计值用作求解器查询的数量的代理,该查询可能是给定变量的一部分。当两个状态的不同变量在以后的查询中不经常出现时,这两个状态是合并的好选择。
Verittesting:基于简单语句和困难语句之间的区别实现了一种合并启发式的形式,后者涉及间接跳转、系统调用和其他难以实现精确静态分析的操作。静态合并是对简单语句序列执行的,使用ite表达式捕获其效果,而每当遇到难以分析的语句时,就会进行逐路径符号探索
动态状态合并
引入动态合并,无论搜索策略施加的探索顺序如何,它都可以工作。假设符号引擎维护状态的工作列表和它们的前一个有限的历史。当引擎必须选择下一个要探索的状态时,它首先检查工作列表中是否有两个状态 $s_1$ 和 $s_2$,它们不匹配合并,但 $s_1$ 和 $s_2$ 的前身匹配合并。
如果 $s_2$ 和 $s_1$ 的后继节点之间的预期相似度也很高,则算法通过将 $s_1$ 的执行推进固定的步数来尝试合并。这抓住了一个观点,即如果两个状态相似,那么它们各自的继任者也可能在几步之内变得相似。如果合并失败,算法会让搜索启发式选择下一个要探索的状态。
利用程序分析和优化技术
程序切片
分析从程序行为的一个子集开始,从程序中提取忠实地代表该行为的最小指令序列。这些信息可以在几个方面帮助符号引擎:如,利用向后程序切片来限制对特定目标程序点的符号探索。
污点分析
试图检查程序的哪些变量可能包含来自潜在危险的外部来源(如用户输入)的值。分析既可以静态执行,也可以动态执行,后者产生更准确的结果。在符号执行的上下文中,污染分析可以帮助引擎检测哪些路径依赖于污染值。例如,一方法侧重于分析跳转指令被污染的路径,并使用符号执行来生成漏洞。
Fuzzing
这种软件测试方法随机改变用户提供的测试输入,导致崩溃或断言失败,可能会发现潜在的内存泄漏。模糊测试可以通过符号执行来增强,以收集输入的约束,并取消它们以生成新的输入。
另一方面,符号执行器可以通过模糊测试来增强,从而在探索中更快、更有效地到达更深的状态。
分支预测
通过避免跳过非常小的代码段来减轻流水线执行中的错误预测惩罚:例如,控制流分支结构(如C三元操作符)可以用谓词选择指令替换。
当交叉检查使用符号执行的程序的两个实现时,采用这种策略所要探索的路径数量呈指数级减少。
类型检查
符号分析可以有效地与类型检查混合使用。如,类型检查可以确定难以进行符号分析的函数的返回类型,执行器可能会使用这些信息来修剪某些路径。
差分程序(Program Differencing)
依赖性分析可以识别受代码编辑影响的分支和数据流。定向增量符号执行静态地识别受变化影响的CFG节点,并使用这些信息驱动仅对那些行使未发现的受影响节点序列的路径进行探索
编译器优化(较少)
6 约束求解
优化方法
求解器和符号执行器都遵循的一种常见优化方法是将约束简化为更简单的形式。例如,表达式重写优化可以应用优化编译器的经典技术,如常量折叠、强度降低和线性表达式的简化(e.g. KLEE)。
EXE引入了一种约束独立性优化,该优化利用了这样一个事实,即一组约束可以经常被划分为多个独立的约束子集。这种优化与查询结果缓存策略很好地交互,并且在引擎询问求解器特定约束的可满足性时提供了额外的优势,因为它从查询中删除了不相关的约束。事实上,独立的分支(在实际程序中经常出现)可能会导致不必要的约束,这些约束会迅速积累起来。
隐含值具体化(KLEE采用):约简技术可以利用的另一个事实是,程序的自然结构可能导致在执行过程中为某些变量引入更具体的约束。由于路径条件是通过将新项连接到现有序列来生成的,因此重写和优化现有约束可能成为可能。(e.g. 添加 x := 5 的等式约束可以将 x > 0 约束简化为 true / 将符号 x 替换为涉及它的其他后续约束中的相关具体值)
约束解的重用:基于约束的语义或语法等价
- EXE 缓存约束解和可满足性查询的结果,以便尽可能地减少调用求解器的需要。缓存由服务器进程处理,该进程可以接收来自执行引擎的多个并行实例的查询,每个实例探索不同的程序状态。
- KLEE 实现了一种称为反例缓存的增量优化策略。使用缓存,约束集被映射到具体的变量赋值,或者在约束集不能满足时映射到一个特殊的空值。子集 <-> 约束集
- 记忆符号执行(Memoized symbolic execution)的动机是由于观察到符号执行经常导致重新运行大部分相似的子问题,例如,找到一个错误,修复它,然后再次测试程序以检查修复是否有效。在路径探索过程中所采取的选择被紧凑地编码在前缀树中,这使得在连续运行中重用先前计算的结果成为可能。
惰性约束(Lazy Constraints)
对约束求解器查询采用超时方法。在他们最初的实验中,作者将大多数超时归因于符号除法和余数操作,最糟糕的情况发生在无符号余数操作的分母上有一个符号值时。因此,他们实现了如下的解决方案:当执行器遇到涉及昂贵符号操作的分支语句时,它将同时采用true和false分支,并在路径条件中添加对昂贵操作结果的延迟约束。当探索达到满足某些目标的状态时(例如,发现错误),算法将检查路径的可行性,如果在实际执行中被认为不可达,则将其抑制。
与急于检查分支可行性的方法(第5.1节)相比,懒惰策略可能导致大量的活动状态,从而导致更多的求解器查询。然而,作者报告说,延迟查询在许多情况下比它们的即时查询更有效:在延迟约束之后添加的路径约束实际上可以缩小求解器的解决方案空间。
符号向后&前符号执行的组合
在第一阶段,从一个目标点执行SBE,并为每个跟随的路径收集跟踪。如果在反向探索期间遇到任何有问题的约束,引擎将通过向跟踪添加特殊事件将其标记为可能满足的约束,并继续其反向遍历。每当沿着以下任何路径到达程序的入口点时,就开始第二阶段。引擎具体地评估收集的跟踪,试图满足在第一阶段标记为有问题的任何约束。这是使用启发式搜索完成的。与传统的共融执行相比,共融执行的一个优点是可以避免探索一些不可行的路径。例如,无论如何到达语句,向后阶段都可以确定语句由不满意的分支保护,而传统的concolic执行器仅在到达语句时才会在每个路径上检测不可行性,这对于路径“深处”的语句是不利的。
void test(int x) {
if (x > 10) {
if (x < 5) {
// 目标点:ERROR
ERROR;
}
}
}第一阶段:反向符号执行:
- 从
ERROR语句开始反向执行。 - 路径条件为
x < 5和x > 10。 x < 5和x > 10是矛盾的(不可满足的),所以将该条件标记为问题约束,并继续反向遍历。
第二阶段:具体正向执行:
- 当反向执行到达程序的入口点时(即函数开始处),开始具体正向执行。
- 具体正向执行尝试满足在反向阶段标记为问题的约束(
x < 5和x > 10)。 - 启发式搜索发现这是不可行的路径,因此避免了探索这条路径。
7 验证语言
Solidity to Boogie(Solidifier)
Boogie语法结构:

[Type] Type'表示从Type到Type'的总映射
Boogie程序声明全局变量和过程(procedure,其声明局部变量和描述其行为的语句列表)
Address 与 Solidity 的 Address 对应的 Boogie,地址单元包含4个元素的记录:
type(AddressType,枚举包括Unused未使用的地址、SimpleAddress简单地址、合约名称合约实例的地址)balance(余额)members&storage(记录只能合约的状态)
Solidity函数有隐式 this 变量,给出应用该函数的合约实例。
在 Solidifier 完成 Boogie 编码后,Corral 接手并进行验证。Corral 会基于用户选择的验证框架(合约验证框架或函数验证框架)来探索程序的状态空间。

合约验证框架:
- 非确定性地址选择:合约验证框架在分析合约行为时,会随机选择一个地址来实例化合约
C。这意味着框架并不假设合约会部署在哪个特定的地址,而是通过随机选择模拟实际部署时的多种可能性。 - 惰性部署(Lazy Deployment):合约验证框架使用惰性部署技术,即只有在需要时才初始化其他地址的存储和内存。这确保了这些存储和内存已经正确初始化,并且类型正确。这种方式节省了资源,同时模拟了实际部署中的情况。
- 主过程(Main Procedure):主过程在一个全局变量
main_contract指向的地址上创建一个合约C的实例。接下来,它会随机执行一系列的接口函数(例如公开可访问的函数),确保这些函数调用是在合法的、可达的状态下进行的。 - 存储和余额的混乱处理(Havocing):每当调用一个新的接口函数时,合约验证框架会随机选择函数的参数,并且除了
main_contract之外,会随机改变所有其他地址的存储和余额。这种处理方式模拟了区块链上其他交易可能对主合约的影响,例如转移资金或触发其他合约的函数。

函数验证框架:
- 单函数分析:与合约验证框架不同,函数验证框架专注于分析单个函数
f的行为。这种分析不假设合约实例C处于一个良好的、常规的状态下,而是从一个随机初始化的状态开始执行这个函数。 - 混乱处理:类似于合约验证框架,函数验证框架在每次函数调用之前也会混乱处理其他地址的存储、内存和余额,但它会保持存储和内存的结构和类型正确。这种方法模拟了某些随机的执行情况,特别是在可能的极端条件下。

Symbooglix
Move Prover / SOLC-VERIFY,利用Boogie语言作为中间验证语言验证,包括Symbooglix、Corral、VeriSol。
Why3, Whiley, or proof assistants like Isabelle/HOL or Coq
中间验证语言(IVL)通过将现实世界编程语言的语义处理与用于评估程序正确性的方法解耦,简化了构建程序分析工具的任务。
前端将输入的程序从一种编程语言(e.g. C)进入IVL,后端对IVL程序进行分析。
Symbooglix是开源Boogie符号执行引擎,用 C# 编写。
Boogie语言用法:https://boogie-docs.readthedocs.io/en/latest/LangRef.html
havoc命令接受一系列变量名,并为每个变量设置一个不确定的值- 映射允许对数组和堆数据建模
- 声明全局变量,并使用公理进行限制
对于每个探索的路径,Symbooglix会跟踪执行状态(程序计数器、堆栈和全局变量),以便在以后的阶段恢复执行。
goto 分支是无条件的,可利用无条件分支对程序行为进行抽象建模
核心指令是 assume 和 assert:
assume检查表达式e在当前状态下是否可满足assert检查是否e和-|e是否可满足- 若
-|e可满足,断言失败,被分析程序有误 - 若
e可满足,将e与路径条件连接,继续分析
- 若
require 子句:
- 程序进入的
require子句的目的是约束初始程序状态,因此它被视为假设 - 所有其他
require子句都被视为过程条目上的断言
路径探索:DFS 的变体(变体目的是防止搜索陷入循环中)
为了回答探索过程中的可满足性查询,并获得收集到的约束集的具体解,约束以标准 SMT-libv2 格式打印,然后传递给 SMT 求解器。实现使用 Z3 约束求解器。
假设不一致性(Inconsistent assumptions):Boogie 语言与传统语言不同,整个程序的执行受制于一组初始约束,由公理指定。如果初始约束不一致(false),程序是 vacuously 正确的,防止这种情况,Symbooglix支持一种可选模式,在执行开始之前检查初始约束的一致性。
优化(Optimisations):
- 唯一的全局常量约束表示
- 非必要声明删除
Goto-assume可预见性:- 碰到
goto,检查assume的可满足性,减少无效状态的生成
- 碰到
- 表达式简化
- 由于实现语言
c#使用截断除法,因此我们必须根据截断除法实现欧几里得除法,以为div和mod提供恒定的折叠
- 由于实现语言
约束独立性
- 消除对确定给定查询可满足性没有必要的约束
- 优化通过考虑一组使用的变量和未解释的函数来传递地计算依赖约束,直到达到一个固定点(fixed point)
具体索引处理数组访问的方式(参考
KLEE)- 对于具体索引的写入,我们不更新表达式树,而是存储这些具体写入的对
高效的执行状态克隆
- 我们使用
c#不可变数据结构实现了更有效的执行状态克隆 - 对于映射的内部表示(不是不可变的),我们添加了一个简单的写时复制机制,类似于
KLEE用来表示内存对象的机制
- 我们使用
Boogie语法
内置参数类型:
bool、int、real三个- 比特向量类型(
bv<N>形式的位向量类型族,其中<N>是位向量的宽度) - 映射类型(
Map)
// Variable x maps integers to boolean values
var x:[int]bool;
// Variable a is a nested map that maps
// integers to a map that maps 32-bit wide bitvectors
// to booleans.
// e.g. a[0] 返回 [bv32]bool
var a:[int][bv32]bool;8 实验(Boogie example)
Symbooglix
参考指令:创建一个指向 z3 可执行文件的符号链接(或复制)并将其放在以下目录中:
sbx@13cf0ea8572f:~/symbooglix$ ln -s /usr/bin/z3 src/SymbooglixDriver/bin/Debug/z3
sbx@13cf0ea8572f:~/symbooglix$ ln -s /usr/bin/z3 src/Symbooglix/bin/Debug/z3实验结果
https://github.com/boogie-org/symbooglix/blob/main/test_programs/basic/symbolic/142.bpl
https://github.com/boogie-org/corral/blob/master/test/av-regressions/paper_overview.bpl
| Symbooglix(单位s/result) | Corral(单位s/result) | 是否存在漏洞 | 注释 | |
|---|---|---|---|---|
| 142.bpl | 0.529/n | 0.409/n | n | / |
| DepthLimit.bpl | 0.079/n | 0.400/n | n | / |
| bigCopyWithFlush.bpl | 0.065/y | 0.410/n | y | 数组越界,Corral判断有误 |
| bv_straight.bpl | 0.016/y | 0.420/y | y | 断言失败 |
| havoc.bpl | 0.018/y | 0.410/y | y | 不确定性 |
| corral/test/av-regressions/eeSlice2.bpl | 0.050/y | 0.450/y | y | / |
| corral/test/av-regressions/t1.bpl | 0.046/y | 0.394/y | y | / |
| corral/test/av-regressions/t4.bpl | 0.028/y | 0.433/y | y | / |
| corral/test/av-regressions/paper_overview.bpl | 0.048/y | 0.460/y | y | / |

